
티스토리 뷰
[Digital 회로 설계] 검증용 SRAM model 직접 만들기 - Single port SRAM
DreamSailor 2021. 1. 2. 17:47
IDM 회사의 디지털 회로 설계 부서에 들어가거나 팹리스 업체에서 일하게 된다면, 검증용 SRAM 모델은 대부분 셋업 되어 있을 것이라 생각한다. SRAM 모델은 어떤 공정을 사용할지 정해지기 전이나 메모리 spec이 확정되지 않았을 때, RTL 검증 환경을 만드는 과정에서 유용하게 사용된다. 신입사원 꼬꼬마 시절엔 나도 그냥 아무 생각 없이 가져다 썼던 것을 이제야 직접 만들어 보게 되었다.
메모리의 종류나 SRAM의 특성 등에 대해서는 여기서 자세히 다루지는 않을 것이다. 간략히 말하자면, SRAM은 래치에 데이터를 저장하는 휘발성 메모리이고, line buffer나 FIFO와 같이 데이터를 임시로 저장해야 하는 경우에 주로 사용하게 된다. 대부분의 사람들이 익숙한 DRAM의 경우에는 보통 logic과 공정이 다르므로, 하나의 웨이퍼에 함께 만들 수 없으며 DMA conrtroller를 통하여 인터페이스를 해줘야 한다. 그러므로 디지털 회로 설계에서 데이터를 저장하기 위해서는 비교적 구현이 간편한 SRAM이 많이 사용된다.

싱글이냐 듀얼이냐?
필자가 대학에 재학 중이던 시절에 처음으로 듀얼 코어 프로세서가 나왔던 것으로 기억한다. 나름 혁신적인 시도였지만, 단순히 CPU 코어를 2개 때려 박은 녀석으로, 발열이 어마어마했었다. 병렬 처리 기술이 발전하면서, 현재는 다중 코어가 보편화됐지만 코어 2개로 방안이 훈훈해지던 그런 시절도 있었다. 잠시 샛길로 내용이 빠졌지만 듀얼이란 것은 '이중의, 두 배의'라는 뜻으로 Dual port SRAM은 Single port SRAM보다 2배 많은 port를 가지고 있다.

아래 그림을 보면, Dual port SRAM이 정확히 포트 개수가 2배인 것을 알 수 있다. 어떤 애플리케이션을 구현할 것인가에 따라 선택을 하면 되는 부분이지만 포트가 많은 만큼 Daul port SRAM의 크기가 상대적으로 크다는 것을 염두에 두어야 한다. Single port SRAM은 하나의 클럭 사이클에 Write와 Read 동작을 동시에 할 수 없으나, Dual port SRAM은 동시에 두 가지 동작이 가능하므로, throughput(처리율) 측면에서 장점이 있다.


CS와 WE로 구성되는 메모리 프로토콜
메모리 프로토콜은 그리 복잡하지 않다. 해당 메모리를 선택할 때 사용되는 CS(Chip Select) 신호와 Write/Read를 구분하는 WE(Write Enable) 신호가 기본이고, BWE(Bit Write Enable)은 메모리 컴파일러 옵션에서 선택할 수 있는 사항이다. 만약 회로가 active-low로 동작한다면 신호의 이름에 postfix인 n(negative)를 달아주는 게 보통이다. 이는 Vlow(0)가 입력으로 들어올 때, 활성화된다는 의미다.
메모리에 접근하기 위해서는 주소 값을 전달해야 하며, 이 값이 디코딩을 거쳐 해당하는 메모리 셀을 선택하여 데이터를 저장하거나 가져오게 된다. 이러한 일련의 과정들을 나타낸 timing diagram을 아래에 첨부하였다. 크게 write phase와 read phase로 나눠서, 동작을 살펴보자.

위의 예시에서는 address를 1씩 순차적으로 증가시키며, 메모리에 저장하고 싶은 데이터를 입력하였다. 메모리를 선택하기 위해 CSn이 0으로 깔렸으며, write를 위해 WEn도 0으로 입력되었다. Bit Write는 원하는 Bit만 선택하여 Write 하는 기능이며, 여기서는 사용하지 않으므로 전부 0으로 내려주었다. 메모리 모델에서는 저장된 data를 내부 array에 담고 있다가 Read phase에서 address에 맞춰서 출력한다.

Write phase와 다른 점은 WEn이 Vhigh(1)로 유지되고 있다는 것이고, address 입력의 다음 클럭 사이클에 rdata port로 데이터가 출력되고 있음을 알 수 있다. 즉, write 동작 때는, address가 입력되는 시점과 동일한 타이밍에 데이터가 써지며, read 동작 때는, address 입력 시점의 다음 사이클에 데이터가 읽어진다.

자, 이제 작성한 코드를 확인할 시간이다.
너무 간단해서, 놀랄 수도 있겠지만, 이게 전부다.
▼ SRAM model 예제 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
module tb_sram
#( parameter BW = 32,
parameter ADR = 8,
parameter AMAX = 256
)
(
// input
input clock,
input CSn,
input WEn,
input [BW-1:0] BWEn,
input [ADR-1:0] addr,
input [BW-1:0] wdata,
// ouptut
output [BW-1:0] rdata
);
reg [BW-1:0] r_inner_mem[0:AMAX];
reg [ADR-1:0] r_addr;
always @(posedge clock) begin
if (!CSn) begin
if (!WEn) begin // Write
r_inner_mem[addr] <= #1 wdata & ~BWEn;
end
r_addr <= #1 addr;
end
end
assign rdata = r_inner_mem[r_addr];
endmodule
|
cs |
Bit width, address width, address 최댓값을 parameter로 세팅할 수 있게 했으며, CSn, WEn, BWen에 따라서 array에 데이터가 저장될 수 있게 구현하였다. 여기서 한 가지 유의해야 할 점은 Bit Write를 위해서는 반드시 bit 연산자를 사용해야 한다는 것이다. 만약 신호 반전 operator를 '~'이 아닌, '!'을 사용한다면 의도치 않은 오동작을 초래할 수 있다. 궁금하신 분이 있다면 바꿔서 테스트해보는 것도 좋다.
rdata는 입력 address를 1 cycle 채서 만든 r_addr 신호로 선택되도록 구현하여, 실제 메모리와 모델이 동일한 동작을 할 수 있게 꾸며보았다. 직접 testbench를 만들어, 간단히 모델을 검증했다. 순차적으로 address를 증가시키고 write phase에서 데이터를 저장하고, 마찬가지로 address를 순차적으로 올려가며 read phase에 데이터가 제대로 출력되는지 확인하였다.
▼ SRAM model 출력 log
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
xcelium> run
0ns --> [Info] Testbench Start!
0ns --> [Info] clock period = 5.0
100ns --> [Info] Write phase Start!
105ns --> [Info] addr = 000, wdata = 000
110ns --> [Info] addr = 001, wdata = 002
115ns --> [Info] addr = 002, wdata = 004
120ns --> [Info] addr = 003, wdata = 006
125ns --> [Info] addr = 004, wdata = 008
130ns --> [Info] addr = 005, wdata = 00a
135ns --> [Info] addr = 006, wdata = 00c
140ns --> [Info] addr = 007, wdata = 00e
143ns --> [Info] Write phase End!
243ns --> [Info] Read phase Start!
245ns --> [Info] addr = 000, rdata(n-1) = 00e
250ns --> [Info] addr = 001, rdata(n-1) = 000
255ns --> [Info] addr = 002, rdata(n-1) = 002
260ns --> [Info] addr = 003, rdata(n-1) = 004
265ns --> [Info] addr = 004, rdata(n-1) = 006
270ns --> [Info] addr = 005, rdata(n-1) = 008
275ns --> [Info] addr = 006, rdata(n-1) = 00a
280ns --> [Info] addr = 007, rdata(n-1) = 00c
285ns --> [Info] addr = 007, rdata(n-1) = 00e
285ns --> [Info] Read phase End!
485ns --> [Info] Testbench End!
Simulation complete via $finish(1) at time 484500 PS + 0
./testbench.sv:98 $finish;
xcelium> exit
|
cs |
재미있는 사실은 Read phase에서 address와 rdata가 한 cycle씩 어긋나 보인다는 것인데, 이는 앞서 설명한 대로 address 입력 다음 클럭 사이클에서 rdata가 출력되기 때문이므로 정상적인 동작이다.
아래 VCD로 dump 된 waveform을 통해 신호가 어떤 식으로 전달되는지 좀 더 확실하게 알 수 있다.



신입사원 시절, 처음 과제를 맡았을 때 Top engineer가 각자 맡은 IP의 메모리 사이즈를 계산해서 전달해달라는 업무를 지시했던 기억이 난다. 당시에는 선배들의 도움을 받아 어찌어찌 해결했었는데, 이제 와서 생각해보니 간단한 계산을 왜 이리 쩔쩔맸었는지 싶다.
아래에 간단한 예제와 설명을 통해 계산 방법을 정리해 보았다.
실제로는 IP에서 필요한 메모리 spec과 공정에서 지원하는 메모리 컴파일러의 제한사항에 따라서, 메모리를 둘로 쪼개야 하는 경우도 왕왕 존재한다. 여기서는 그런 내용들까지 고려하지는 않고, 단순히 IP에서 필요한 메모리 계산법만 다뤄보도록 한다.
- BW(BitWidth) : 한 번에 저장할 데이터의 bit width 총 합
- Word : Address 개수
만약, 640(H)x480의(V) 입력 spec을 갖는 4 채널의 10bit 데이터 스트림을 갖는 애플리케이션의 line buffer 사이즈를 구해야 한다고 가정했을 때,
10(data bit width)*4(채널 수) = 40
640(H)/4(채널 수) = 160
BW = 40, Word = 160 크기를 갖는 메모리면 된다.
하지만, 이런 식으로 line buffer를 구현하면 on the fly로 입력되는 데이터를 저장할 하나의 line buffer가 또 필요하다. 아래 그림을 살펴보자.

그러므로, 두 번의 클럭 사이클 당 data를 모아서 write 하고, read/write를 동일한 phase에 진행될 수 있도록 컨트롤해야 한다.

두 클럭 당 한번 write 하므로, address는 절반이면 충분하다. 즉, Word size가 1/2이 되는 대신, bit width는 2배가 된다. 앞선 예에서 메모리 사이즈를 다시 계산해보면 다음과 같다.
10(data bit width)*4(채널 수)*2(두 cycle 당 1 write) = 80
640(H)/4(채널 수)/2(두 cycle 당 1 write) = 80
BW = 80, Word = 80 크기를 갖는 메모리면 된다.
두 cycle 당 모아서 한 번 write 하는 콘셉트로 timing diagram을 그려보면, 아래와 같다. 두 번째 line에서 data를 write 하는 시점과 메모리에 저장된 첫 번째 line의 데이터를 read 하는 시점이 다르므로, read/write를 동시에 할 수 있다.
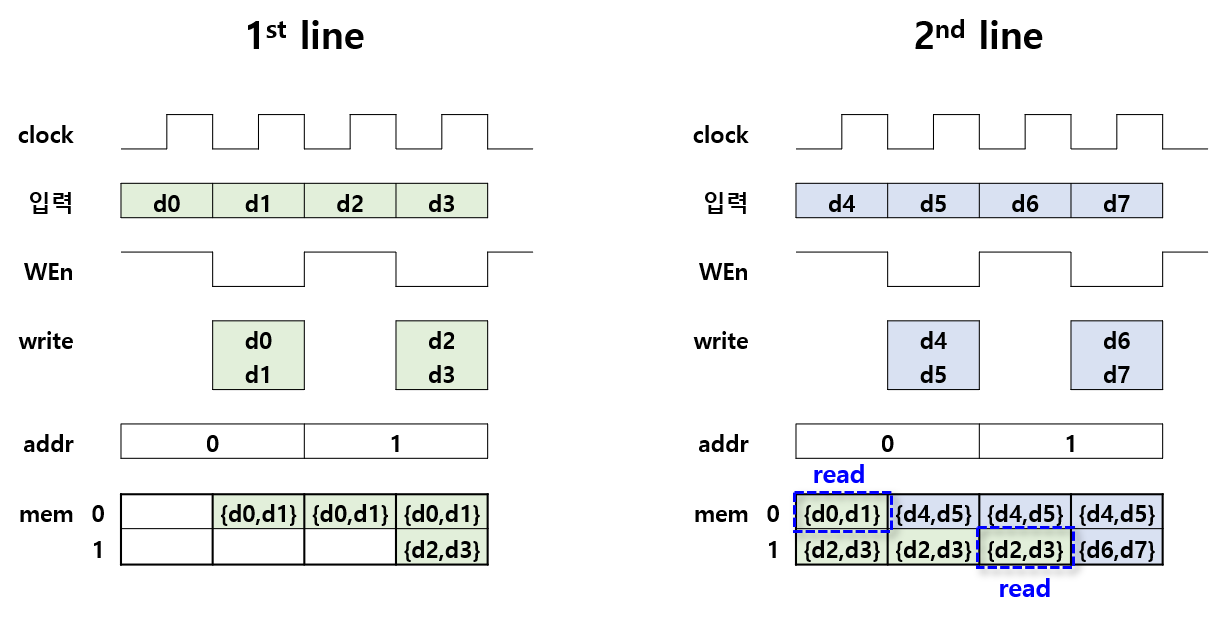
맺음말
검증용 SRAM 모델을 소개하는 것부터 시작하여 line buffer 설계를 위한 메모리 사이즈 계산 및 컨트롤까지 꽉꽉 채운 포스팅이었다. SRAM은 디지털 회로 설계에 있어, 사용하지 않는 IP를 찾아보기 어려울 정도로 필수적인 요소이다. 특히 커널 기반의 필터 연산을 하는 영상처리 ISP에는 무조건 사용된다고 봐도 무방하다.
추가로, SRAM 모델뿐 아니라, AMBA BUS 모델이나 I2C/I3C 모델과 같은 검증용 코드들을 자기 손으로 구현해보는 것이 큰 공부가 될 것이라고 생각한다. 비록 나도 이제야 하나둘씩 구현해보는 처지이지만, 이제 디지털 회로 설계를 시작하는 신입사원들에게는 본인의 실력 향상을 위해 강력 추천하는 바이다.
'Digital design (VLSI)' 카테고리의 다른 글
| [회로 및 시스템] DRAM에 관한 단편적 사실들 (5) | 2022.09.08 |
|---|---|
| [Digital 회로 설계] SystemVerilog로 Testbench 설계하기 3편(Image driver) (7) | 2020.12.14 |
| [Digital 회로 설계] SystemVerilog로 Testbench 설계하기 2편 (7) | 2020.05.16 |
| [Digital 회로 설계] SystemVerilog로 Testbench 설계하기 1편 (6) | 2020.02.09 |
| [Digital 회로 설계] Wavedrom으로 timing diagram 쉽게 그리기 (6) | 2019.03.10 |