
티스토리 뷰

프롤로그
스터디 날짜가 공교롭게도 어린이날과 겹쳐서 한 박자 쉬고, 전체 일정을 한 주 미뤘다.
한 주 쉬고 가는 게 어떠냐는 스터디장님의 제안에 모두가 꿀 먹은 벙어리처럼 있다가,
막상 투표를 여니까 몰표가 나오는 기적을 체험했다.

이번 주는 Tree에 대한 문제 4개, 코딩 테스트로 나올법한 추천수 높은 문제 1개였다.
Tree는 재귀를 이용해야 했는데, 처음에 감을 못 잡아서 많이 헤맸다.
문제를 다 풀어 본 지금에서야 어떻게 접근해야 하는지 조금 감이 잡히는 정도?
Tree에 대한 컨셉
- Tree란?
: 나뭇가지가 root(뿌리)에서 시작해서 가지를 치면서 뻗어나가듯,
이러한 계층구조를 갖는 graph의 일종을 tree라고 한다.
- 순회의 방법
: Tree는 크게 전위(preorder), 중위(inorder), 후위(postorder), 층별(level order)의 4가지 순회 방법을 갖는다.
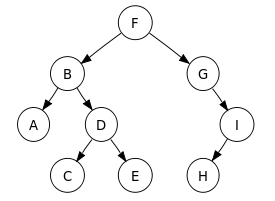
- 전위 순회(preorder): 뿌리(root)부터 방문 (root -> left -> right)
ex) F -> B -> A -> D -> C -> E -> G -> I -> H - 중위 순회(inorder): 왼쪽 sub-tree를 먼저 방문 후, 뿌리(root)를 방문 (left -> root -> right)
ex) A -> B -> C -> D -> E -> F -> G -> H -> I - 후위 순회(postorder): 왼쪽과 오른쪽 sub-tree를 방문 후, 뿌리(root)를 방문 (left -> right -> root)
ex) A -> C -> E -> D -> B -> H -> I -> G -> F - 층별 순회(level order): 상위 node부터 하위 node 방향으로 차례대로 방문
ex) F -> B -> G -> A -> D -> I -> C -> E -> H
- 탐색의 방법
: DFS(Depth-First Search)와 BFS(Breadth-First Search)로 나눌 수 있는데,
DFS는 깊이 우선 탐색으로, 최대한 깊이 내려간 다음 갈 곳이 없을 때 옆으로 이동하는 것이고,
BFS는 너비 우선 탐색으로, 같은 위계(depth)를 먼저 탐색하고 아래로 내려가는 것이다.
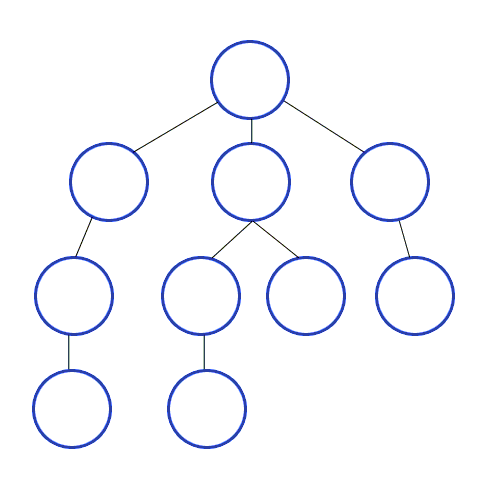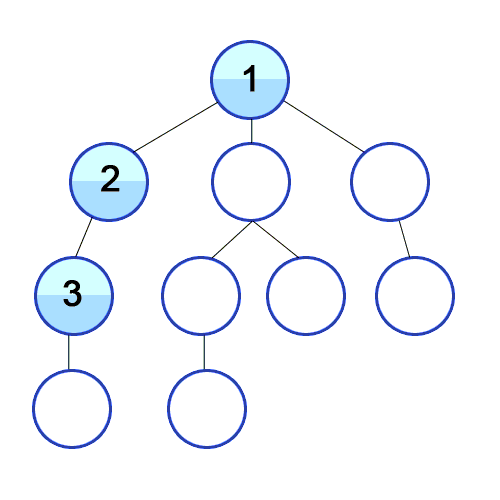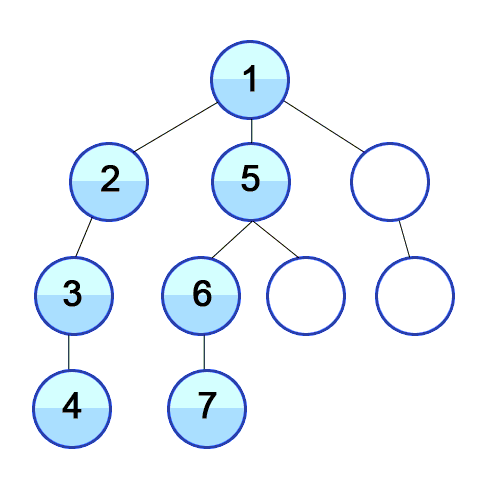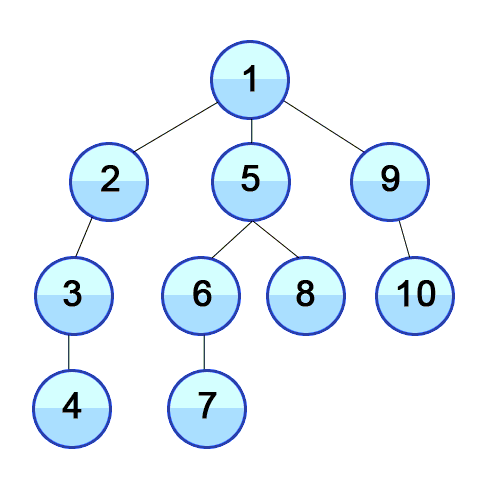 |
 |
| DFS(깊이 우선 탐색) | BFS(너비 우선 탐색) |
출처 : https://developer-mac.tistory.com/64
617. Merge Two Binary Trees - Easy 🍭
1. 문제 정의
: 두 개의 이진 트리 노드가 주어졌다.
동일한 위치(hierarchy, position) 면, 두 값을 더하고
노드가 하나의 트리에만 있으면 그 값을 사용한다.
2. 아이디어 스케치
: 너무 오래전이라 기억이 가물가물하지만,
자료구조 수업 때 들었던 내용을 상기하며 재귀로 문제를 풀려고 시도했다.
(1) 두 트리를 동시에 순회한다.
(2) 아래 조건을 만족하면, 첫 번째 tree에 바로 업데이트한다.
if (모두 값이 존재하면) then 두 값을 합한다.
else if (한쪽에만 값이 존재하면) then 존재하는 트리 선택
else (둘 다 null이면) then 그대로 둔다.

3. 내가 작성한 날 것 그대로의 코드 - O(N)/O(N)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
#import math
class Solution:
def mergeTrees(self, root1: Optional[TreeNode], root2: Optional[TreeNode]) -> Optional[TreeNode]:
if (root1 is None):
return root2
if (root2 is None):
return root1
root1.val += root2.val
root1.left = self.mergeTrees(root1.left, root2.left)
root1.right = self.mergeTrees(root1.right, root2.right)
return root1
|
cs |
4. 복기 및 배운 점
: 이 문제에 상당한 시간을 소모했는데, 일단 트리와 재귀에 대한 이해가 너무 부족했다.
결국 해답을 참고해서 문제를 해결했고, 어떤 식으로 동작하는지 이해하니
이후 문제부터는 풀이법에 대해 조금 감이 잡혔다.
-> 정말 모르겠으면, 정답을 참고하는 것도 방법이다. (충분한 고민 후에!)
104. Maximum Depth of Binary Tree - Easy 🍭
1. 문제 정의
: 이진 트리의 max depth를 반환한다.

2. 아이디어 스케치
: (1) node의 개수만으로는 depth 판단이 불가하다.
(2) 순회하면서 깊어질수록 depth counter를 1씩 증가시키고,
left, right node를 비교하여 큰 값을 return 하며 재귀를 빠져나오는 식으로 구성
3. 내가 작성한 날 것 그대로의 코드 - O(N)/O(N)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def sizeTree(self, root):
if (root.left is not None):
l = self.sizeTree(root.left) + 1
else:
l = 1
if (root.right is not None):
r = self.sizeTree(root.right) + 1
else:
r = 1
return l if (l >= r) else r
|
cs |
4. 복기 및 배운 점
: 1번 문제에 비해 비교적 쉽게 문제를 해결할 수 있었다.
1447. Count Good Nodes in Binary Tree - Medium ⛅
1. 문제 정의
: Good node의 개수를 반환하라.
Good node란, root부터 내려온 현재 node까지 값의 크기를 비교하여,
현재 node보다 큰 값이 없는 경우의 node를 말한다.
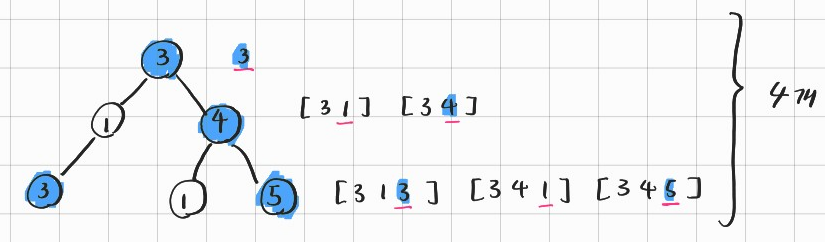
2. 아이디어 스케치
: 순회하면서, 이 전까지의 Max 값도 재귀 함수의 인자로 함께 넣어 준다.
즉, 재귀 함수의 return 값은 아래와 같다.
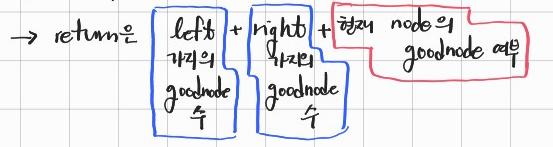
3. 내가 작성한 날 것 그대로의 코드 - O(N)/O(N)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def goodNodes(self, root: TreeNode) -> int:
maxVal = root.val
return self.traversal(root, maxVal)
def traversal(self, root: TreeNode, prevMax) -> int:
GoodNode = 1 if (root.val >= prevMax) else 0
maxVal = root.val if (GoodNode == 1) else prevMax
print('root={0}, prevMax={1}, maxVal={2}'.format(root.val, prevMax, maxVal))
if root.left is not None:
l = self.traversal(root.left, maxVal)
else:
l = 0
if root.right is not None:
r = self.traversal(root.right, maxVal)
else:
r = 0
print('l={0}, r={1}, GoodNode={2}'.format(l, r, GoodNode))
return l + r + GoodNode
|
cs |
4. 복기 및 배운 점
: 트리 문제를 풀면서, 재귀 함수에 대한 이해도가 조금 높아졌다는 느낌적 느낌(?)을 얻었다.
스터디원의 대부분이 Max 값을 같이 전달하는 식으로 문제를 접근하였다.
98. Validate Binary Search Tree - Medium ⛅
1. 문제 정의
: 타당한 BST(Binary Search Tree)인 지 판단하라.
타당한 BST의 성립 조건은 아래와 같다.

2. 아이디어 스케치
: 두 개의 파트로 구성한다.
(1) False check
: Stack을 활용하여, tree를 순회하며 부모 node의 값도 저장한다.
Stack 된 부모 node까지 비교하면서, BST 구조를 따르지 않으면 false로 판단한다.
(2) 순회
: tree 구조를 left->right 순으로 순회한다.
1단계 깊어질 때마다, 부모 node와 branch의 방향을 stack에 push 한다.
1단계 상위로 나올 때, stack에서 현재 node를 pop 한다.
3. 내가 작성한 날 것 그대로의 코드 - O(N^2)/O(N)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isValidBST(self, root: Optional[TreeNode]) -> bool:
stParents = []
return True if (self.traversal(root, stParents) == 0) else False
def traversal(self, root, stParents):
falseNum = 0
print('root = {0}, stParents = {1}'.format(root.val, stParents))
# False checker
if(stParents is not None):
for rootP in stParents:
if (rootP[0] == 0): # left
if (root.val >= rootP[1]):
return 1
else: #right
if (root.val <= rootP[1]):
return 1
# in-order traversal
if (root.left is not None):
stParents.append((0, root.val))
falseNum += self.traversal(root.left, stParents)
if (root.right is not None):
stParents.append((1, root.val))
falseNum += self.traversal(root.right, stParents)
if (stParents):
stParents.pop()
return falseNum
|
cs |
4. 더 좋은 코드 - O(N)/O(N)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import math
class Solution:
def isValidBST(self, root: TreeNode) -> bool:
def inOrder(root):
if (not root): # is root None?
return True
if (not inOrder(root.left)):
return False
if (root.val <= self.prev):
return False
self.prev = root.val
return inOrder(root.right)
self.prev = -math.inf # minimum value
return inOrder(root)
|
cs |
*해당 코드는 스터디원께서 발표한 내용을 기반으로 다시 작성한 것임을 알립니다.
5. 복기 및 배운 점
: stack으로 문제를 풀면서, 부모 node까지 모두 비교를 진행하여, 시간 복잡도가 N의 제곱까지 소요됐다.
다른 분들은 중위 순회 방식을 사용하면서, node당 한 번의 비교만 진행하여 시간 복잡도를 N으로 줄였다.
나로선 더 좋은 방법이 있는지 고민할 여력이 없어서 조금 아쉬운 결과를 얻고 말았다.
437. Find All Anagrams in a String - Medium ⛅
1. 문제 정의
: Anagram이란, 철자를 분해하여 새로운 단어를 만드는 것이다.
ex) Rescue -> Secure
두 string(s, p)이 주어지는데, s string에 들어 있는 p string의 anagram index를 list형태로 반환하라.
2. 아이디어 스케치
: hash table에 넣고, window를 하나씩 옮겨 가며 찾는 방식으로 구현한다.
3. 내가 작성한 날 것 그대로의 코드 - Time over...
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import copy
class Solution:
def findAnagrams(self, s: str, p: str) -> List[int]:
hashTable = list([0 for i in range(26)])
hashTable2 = list([0 for i in range(26)])
wdwSize = len(p)
anaIndex = []
for letter in list(p):
hashTable[self.calKey(letter)] += 1
for n in range(len(s)-wdwSize+1):
cmpWord = s[n:n+wdwSize]
for letter in list(cmpWord):
hashTable2[self.calKey(letter)] += 1
if (hashTable == hashTable2):
anaIndex.append(n)
hashTable2 = list([0 for i in range(26)])
return anaIndex
def calKey(self, letter):
return int((ord(letter)-97)%26)
|
cs |
4. 더 좋은 코드 - O(N)/O(N)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
from collections import Counter
class Solution:
def findAnagrams(self, s: str, p: str) -> List[int]:
lenS, lenP = len(s), len(p)
# exception condition
if (lenS < lenP):
return []
countP = Counter(p)
countS = Counter()
output = []
for i in range(lenS):
countS[s[i]] += 1
if (i >= lenP):
if (countS[s[i - lenP]] == 1):
# Unique value
del countS[s[i - lenP]]
else:
# Duplicated value
countS[s[i - lenP]] -= 1
if (countP == countS):
output.append(i - lenP + 1)
return output
|
cs |
*해당 코드는 스터디원께서 발표한 내용을 기반으로 다시 작성한 것임을 알립니다.
5. 복기 및 배운 점
: Time limit over라는 결과를 받아 해결하지 못한 문제이다.
hash table을 각각 전부 비교하는 형태로 구현하면, 시간 소요가 많아지므로 올바른 접근이 아니었다.
문제를 해결한 스터디원은 window를 옮겨가면서, 불필요한 이전 값을 지워주는 형태로 구현하였다.
결과적으로 한 번의 Scan으로 원하는 목적을 달성할 수 있게 된다.
'Algorithm' 카테고리의 다른 글
| [LeetCode] H/W 개발자의 Sorting 문제 풀이 (0) | 2022.05.21 |
|---|---|
| [LeetCode] H/W 개발자의 Stack & Queue 문제 풀이 (0) | 2022.05.03 |
| [LeetCode] H/W 개발자의 Array & Linked list 문제 풀이 (1) | 2022.04.28 |