
티스토리 뷰

여는 글
작년까지만 해도 딥러닝의 '딥' 자도 모르던 내가 이제는 논문과 github에 올라온 소스 코드를 보고 따라 해 볼 정도의 수준은 되었다. 어떻게 보면 회사에서 했던 일과는 연속성이 떨어지는 쪽으로 연구 주제를 정한 셈이고, 따라가기에 힘이 많이 부치지만 배우는 것도 그만큼 많다고 생각한다. 부족한 지식을 채우기 위해 딥러닝 스터디를 거의 1년 가까이 진행해 오고 있다. 책은 총 3권 독파했고, 현재는 파이썬 부트코스 100 days 스터디를 좋은 사람들과 함께 진행 중이다.
👇 스터디에 활용한 딥 러닝 도서가 궁금하다면 클릭
- 밑바닥부터 시작하는 딥러닝:파이썬으로 익히는 딥러닝 이론과 구현 - 한빛미디어
: 딥러닝 초보자에게 바이블과 같은 위상을 가진 책. 텐서플로나 파이토치와 같은 라이브러리를 사용하지 않고, 직접 파이썬으로 코드를 구현하며 배울 수 있다는 장점이 있다. - 파이썬 머신러닝 완벽 가이드 - 위키북스
: 사이킷런을 활용하여 딥러닝 외의 고전적인 머신 러닝 기법도 함께 배울 수 있다. 머신 러닝에 대한 기초가 부족하다면 꼭 읽어보면 좋을 책. - 비전 시스템을 위한 딥러닝 - 한빛미디어
: 컴퓨터 비전에 특화된 다양한 어플리케이션에 활용되는 딥 러닝 기법을 배울 수 있으며, 실습 보다는 충실한 이론 설명이 더 장점인 책이라고 생각한다.
👇 파이썬 부트코스 100 days 강좌가 궁금하다면 클릭
https://dreamsailor.tistory.com/43
[홈프로젝트] Python으로 뽀모도로 타이머 만들기 2화 실천편
여는 글 지금 이 글을 쓰는 중에도 뽀모도로 타이머는 돌아가고 있다. 무려, 2019년 12월에 '뽀모도로 타이머 만들기 기획편'을 올렸으니, 대략 3년 가까운 시간이 지났다. 언제쯤 후속 포스팅이 올
dreamsailor.tistory.com
다들 어느 정도 딥 러닝 기초에 대한 이해는 된 상태이기에, 이제는 배운 지식을 활용할 실전에 목말라 있었다. 바로 데이터 경진대회 등에 도전하기에는 경험이 부족하다고 판단되어, Kaggle에 올라온 dataset으로 문제를 풀면서 경험을 쌓기로 결정했다.
Kaggle이란?
데이터 사이언스나 딥러닝을 공부해본 사람이라면, 한 번쯤 Kaggle challenge에 대해서 들어본적이 있을 것이다. 알고리즘 분야에 백준, 정올, Leet code와 같은 문제 풀이 사이트가 있다면, 데이터 사이언스 쪽에는 Kaggle이 가장 대표적인 플랫폼이라고 보면 된다. Kaggle에는 정말이지 유용하면서 재밌는 양질의 dataset이 넘쳐난다. 참고할 만한 노트북이나 토론 등도 공개되어 있기 때문에, 초심자가 접근하기에도 좋다. Kaggle에서 본인이 올린 노트북이나 토론 등의 추천 수에 따라 메달을 받게 된다. 이 메달이 쌓이면 등급이 올라가게 되고, 이는 본인의 데이터 과학 역량을 증명하는 공식적인 라이선스 역할을 한다.
👇 자세한 내용은 아래 링크 참조
골든래빗 공식 페이지 - [캐글 안내서] 왜 캐글을 해야 할까?
Horses or humans dataset
처음 시작을 끊게 될 Dataset으로 Horses or humans dataset을 선정하게 이유는 스터디원의 추천 때문이었다. 다들 초심자이기에 2진 분류 문제처럼 난이도가 비교적 낮고, 어느 정도 정형화된 이미지 분류로 시작하는 게 좋을 것이라고 의견이 모아졌다. 이 dataset은 정답이 '말 아니면 사람'이기 때문에 2진 분류이며, 2진 분류의 대표적인 dataset으로는 dogs and cats가 있다.
Dataset은 527개의 렌더링된 사람 이미지와 500개의 말 이미지로 구성되어 있다. 사람은 성별과 인종이 다양하게 분포되어 있으며, 다양한 각도 및 포즈로 사람과 물체가 위치하고 있다. 사람과 말은 그 형상이 매우 다르기 때문에 강아지와 고양이를 분류하는 문제보다 훨씬 쉽게 구분이 될 것이라고 생각했다. 그러나 막상 뚜껑을 열어보니 학습이 쉽지 않았다. 언제나 그렇듯이 예상은 빗나가라고 있는 것이다.
모델 선택 - MLP or CNN
MLP는 이미지 분류에는 CNN에 비해 선호되지 않는 편이다. 이미지 특성상 주변 값을 참조하는 것이 필요한데, MLP는 각 feature를 1D로 풀어버리기 때문에 위치 정보를 상실하게 된다. 이에 반해 CNN은 2D로 필터링을 진행하므로, 주변의 픽셀 정보를 사용하여 feature map을 생성하게 된다. 이러한 이유로 대부분의 이미지 처리 관련 딥 러닝 알고리즘은 CNN을 기반으로 하고 있는 것들이 많다. 다만, 지금은 연습하는 과정이기 때문에 MLP와 CNN 모두 사용하여 2진 분류를 해결하는 네트워크를 각각 구현해 보았다.
📄 작성한 MLP pytorch 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten=nn.Flatten(start_dim=2)
self.linear_relu_stack = nn.Sequential(
nn.Linear(48*48, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 16),
nn.Linear(16, 2)
)
def forward(self, x):
x = self.flatten(x)
x = self.linear_relu_stack(x)
x = torch.mean(x, dim=1, keepdim=True)
return x
|
cs |
📄 작성한 CNN pytorch 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn_layer_0 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, stride=1, padding=5 // 2),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=4)
)
self.cnn_layer_1 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=5, stride=1, padding=5 // 2),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
self.cnn_layer_2 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=5, stride=1, padding=5 // 2),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
self.cnn_layer_3 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=5, stride=1, padding=5 // 2),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2)
)
self.fc_layer =nn.Sequential(
nn.Flatten(),
nn.Linear(256 * 1, 48),
nn.Linear(48, 2),
)
def forward(self, input):
output = self.cnn_layer_0(input)
output = self.cnn_layer_1(output)
output = self.cnn_layer_2(output)
output = self.cnn_layer_3(output)
output = self.fc_layer(output)
return output
|
cs |
📄 Transfer learning으로 분류기만 바꾼 ResNet18 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from torchvision import models
import torch
model = models.resnet18(pretrained=True)
import torch.nn.functional as F
class attaching_model(nn.Module):
def __init__(self):
super().__init__()
self.linear2=nn.Linear(512,256)
self.linear3=nn.Linear(256,64)
self.linear4=nn.Linear(64,16)
self.linear5=nn.Linear(16,2)
def forward(self,x):
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
x = F.relu(self.linear4(x))
x = self.linear5(x)
return x
|
cs |
오답 노트
위에 작성된 MLP, CNN 코드는 여러 가지 이상한 부분들이 보이는데, 계속된 시행착오의 최종 결과물이라고 봐도 무방하다. 일단 입력 이미지 사이즈가 dataset의 스펙인 300x300이 아닌 48x48인데, 혹시나 이미지 크기 때문에 학습이 안되는건 아닌지 의심이 들어 patch 형태로 잘라서 학습을 시켰기 때문이다. 다음은 자잘한 내용은 다 생략하고, 시도했던 내용들을 큰 부분 위주로 정리한 기록이다.
처음엔 단순히 이진 분류 문제이기에 MLP로도 어느 정도 학습이 될 것이라고 생각했으나, 결과적으로는 잘 안됐다. VGG나 ResNet과 같은 유명한 네트워크를 사용하지 않고, 대충 CNN layer 쌓고 마지막에 FC layer로 분류기 만들어주면 잘 되겠지 생각했으나 또 실패했다. Dataset을 잘못 만들었나 싶어서 데이터 사이즈도 줄여보고, Gray 채널로 변환해서도 해보고, Normalization을 수정도 해봤으나 전부 실패.
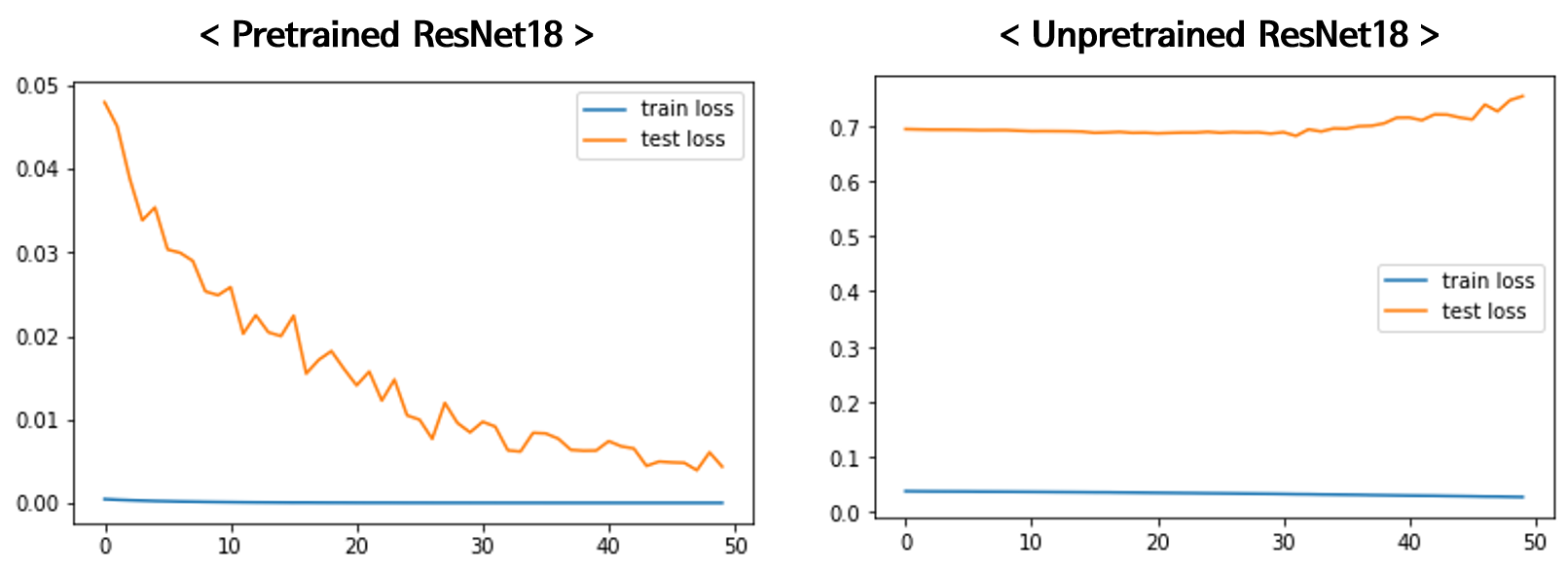
Pretrained된 ResNet18 네트워크를 가져와서 Transfer learning을 돌리니 이제야 제대로 된 결과를 보인다. 그렇다면 내가 작성한 네트워크가 문제가 있었는 지 확인을 위해, 단순히 ResNet18 네트워크로 pretraining을 시키지 않고 학습을 해보니 역시 잘 안된다. 즉, 네트워크의 문제라기보다는 dataset의 성격 자체가 학습이 까다로운 형태가 아닐까 생각되어 다음과 같이 원인을 추측해 보았다.
- 절대적 데이터 양의 부족
- 동일한 형상을 각도만 다르게 해서 찍은 데이터가 많음
- 학습용 데이터에는 배경이 있으나, 테스트 목적의 데이터에는 배경이 없음
Pretrained된 모델은 이미 다양한 데이터셋으로 특징을 잘 구분할 수 있도록 사전에 학습이 되어 있으므로, 추출된 특징 맵으로 분류기만 학습시키면 되기에 비교적 빠르게 좋은 결과를 얻을 수 있었다고 생각한다.
'머신러닝 & 딥러닝' 카테고리의 다른 글
| [후기] 가속기 프로그래밍 겨울캠프에 다녀오다. (4) | 2024.02.27 |
|---|---|
| [스터디 후기] 부스트코스 코칭스터디 - 데이터 사이언스 프로젝트 2024 (0) | 2024.02.26 |
| [책] Efficient Processing of Deep Neural Network - Ch5. Designing DNN Accelerators (1) (0) | 2023.03.05 |
| [PyTorch] Distributed DataParallel로 Multi GPU 연산하기 (4) | 2023.01.18 |
| [책] Efficient Processing of Deep Neural Network - Ch4. Kernel Computation (2) | 2023.01.17 |