
티스토리 뷰

들어가며
느려
느려도 너무 느렸다.
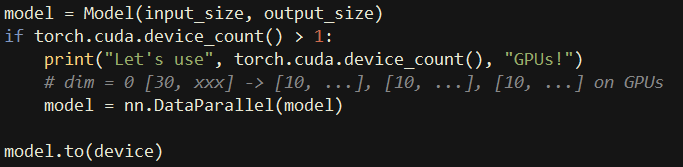
서버에 GPU가 8개씩 달려있으면 뭐 하니, 제대로 쓰질 못하는데. 4K 이미지를 몇 천장을 128x128 사이즈로 잘라서 데이터셋을 만들고, 조금 무거운 모델에 올려서 돌리다 보니 속도가 너무 느렸다. 1 epoch를 도는데, 2시간 가까이 걸리는데 어느 세월에 학습을 다 끝내냔 말이다. 이제는 제대로 Multi GPU를 사용해야 할 때인가 싶어, 폭풍 구글링을 통해 nn.DataParallel을 검색하여 후딱 코드에 박아 넣었다. 좀 빨라지려나 생각했으나 결과는 Fail.
이유가 뭘까?
일단 무지성으로 PyTorch 한국 공식 페이지에 들어가서 Multi GPU 관련 튜토리얼을 쭉 돌려봤다. 인터넷에 돌아다니는 아티클과 테크 리포트 등을 훑어보니, nn.DataParallel은 온전한 멀티 프로세싱이 아니라 멀티 스레딩이라고 봐야 한다는 것이었다. 여기서 간단히 멀티 스레딩과 멀티 프로세싱의 차이를 설명하면 아래와 같다.
nn.DataParallel은 각 GPU 마다 하나의 프로세스가 도는 게 아니라, 학습을 위한 model도 공유하고, mini batch, output activation, back propagation을 위한 loss까지도 서로 공유하면서 멀티 스레딩처럼 동작하는 듯했다. 그래서 엄밀히 말하자면 완벽한 병렬 컴퓨팅이라고 볼 수는 없다. 이런 식으로 Multi GPU가 돌면 내부 I/O를 사용하여 통신이 비교적 원활하다는 장점과 mini batch를 분할하여 각 GPU 메모리에 올리므로, 대용량의 메모리 사용이 필요한 경우 유용하다는 점 외에는 속도 면에서 큰 장점을 갖기엔 어려워 보였다. 또한, Master GPU가 각 과정마다 gathering & update를 해야 하므로 오히려 병목이 생길 수 있다고 생각한다. 아마도 후술 할 Distributed DataParallel 보다 속도가 느린 것도 이러한 이유 때문이라고 추측해 볼 수 있었다.
PyTorch 공식 사용자 모임 페이지에 나와있는 튜토리얼을 보면 잘 아시겠지만, nn.DataParallel은 단 한 줄만 추가해도 잘 동작하므로 사용하기에 아주 간편했다. 다만, Distributed DataParallel은 코드를 수정해야 할 것도 비교적 많고, GPU 간에 통신이 되도록 TCP 주소와 포트 등도 설정해야 한다. 그래서 진입 장벽이 조금 높기는 하지만, 막상 하고 돌아가는 속도를 보니 마음이 아주 편 - 안 해졌다. 그래, 이 정도 속도는 나와줘야 병렬 처리했구나 하고 어디 가서 명함이라도 내밀지.
Distributed DataParallel를 어떻게 돌려야 하는지 설명해 놓은 블로그들은 많기에 여기서는 코드 한 줄 한 줄 설명하는 것은 생략하려고 한다. 기본적인 동작 컨셉은 training을 위한 코드를 main_worker 함수로 감싸고, main 함수에서는 이 main_worker를 torch.multiprocessing.spawn 함수를 통해서 call 하면서 각 GPU ID를 할당하는 방식이다. 이때, argument로 넣어줘야 하는 것들이 rank, world_size, ngpus_per_node 등인데, 생소한 개념이라 이 것만 간단히 짚고 넘어가려 한다.
- world size: 분산 환경에서 사용할 총 GPU 개수. N(nodes) X G(W)
- ngpus_per_node: node 당 GPU 개수. 분산 처리를 수행할 GPU 개수를 입력
- rank: Distributed DataParallel에서 가동되는 process ID
ex) 단순히 GPU 8개로 멀티 프로세싱을 하려면, world size = 8, node = 1, ngpus_per_node = 8로 두면 되고, rank는 각 main_worker에서 해당 GPU ID가 들어갈 수 있도록 코드를 구성하면 된다.
🔻 코드 구현에 도움을 많이 받은 포스팅을 링크해 두었다. (당근마켓 팀 블로그)
🔥PyTorch Multi-GPU 학습 제대로 하기
PyTorch를 사용해서 Multi-GPU 학습을 하는 과정을 정리했습니다. 이 포스트는 다음과 같이 진행합니다.
medium.com
마지막으로 각 PyTorch 라이브러리의 내부를 까보고 forward propagation과 backword propagation 시에 DataParallel과 Distributed DataParallel 사이에 어떤 차이가 있는지 정리한 내용을 공유하며 글을 마무리하려고 한다. 아래 내용만 잘 이해해도 왜 Distributed DataParallel이 더 병렬 GPU 연산에 적합한 방법인지 알 수 있을 것이다.
Forward propagation
nn.DataParallel
- Replicate model: Master GPU가 각 model을 Slave GPU에 뿌려준다.
- Scatter mini-batch: Master GPU가 mini batch를 GPU의 갯수만큼 나눠서 Slave GPU에 뿌린다.
- Parallel apply: 각 GPU 별로 memory에 올라와 있는 model과 mini batch로 forward 방향으로 학습을 진행한다.
- Gather outputs: Slave GPU에서 각각 연산된 출력 activation을 Master GPU가 모은다.

nn.parallel.DistributedDataParallel
- Parallel process: 각 GPU별로 model을 memory에 올린다.
- Scatter mini-batch: full dataset에서 동일한 크기의 mini-batch만큼 각 GPU에 할당한다.
- Parallel apply: Single process와 동일하게 각 GPU 별로 forward 방향으로 학습을 진행한다.
- No Gathering: nn.DataParallel과 다르게 출력 activation을 모으는 작업이 필요하지 않다.

Backward propagation
nn.DataParallel
- Compute loss: Master GPU에서 loss를 계산한다.
- Scatter loss: Master GPU가 각 Slave GPU 별로 해당하는 loss를 뿌려준다.
- Compute gradients: Slave GPU 별로 각 loss를 통해 back propagation 연산을 진행한다.
- Gather & update: Slave GPU에서 최종적으로 계산된 각 layer의 gradient를 Master GPU로 모아준다.

nn.parallel.DistributedDataParallel
- Compute loss: 각 GPU는 output activation으로부터 loss를 계산한다.
- No scattering: nn.DataParallel과 달리 loss를 뿌려줄 필요가 없다.
- Compute gradients: 앞서 계산한 loss를 가지고 back propagation 연산을 진행한다.
- Gradients all-reduce: all-reduce로 전체 GPU간 통신을 통해 gradient를 전달한다.

결론적으로 DistributedDataParallel이 DataParallel 보다 속도가 빠르며, 이상적으로 볼 때는 GPU의 개수만큼 속도가 빨라져야 하지만, 실제로는 그 정도는 아니고 거의 엇비슷한 수준으로 빠르게 학습이 가능하다.
끗
'머신러닝 & 딥러닝' 카테고리의 다른 글
| [후기] 가속기 프로그래밍 겨울캠프에 다녀오다. (4) | 2024.02.27 |
|---|---|
| [스터디 후기] 부스트코스 코칭스터디 - 데이터 사이언스 프로젝트 2024 (0) | 2024.02.26 |
| [책] Efficient Processing of Deep Neural Network - Ch5. Designing DNN Accelerators (1) (0) | 2023.03.05 |
| [책] Efficient Processing of Deep Neural Network - Ch4. Kernel Computation (2) | 2023.01.17 |
| [Kaggle] Horses or humans dataset으로 이미지 분류하기 (0) | 2022.10.23 |