
티스토리 뷰
[책] Efficient Processing of Deep Neural Network - Ch4. Kernel Computation
DreamSailor 2023. 1. 17. 14:55
들어가며
이 책은 딥러닝 가속기를 연구하는 사람이나 이 분야를 업으로 삼고 있는 사람들에게는 바이블과 같은 책이다. 나도 아직 끝까지 다 읽지는 못했지만 방학(이라 읽고 연구 집중 기간이라 쓴다.) 동안 찬찬히 음미하며 읽어볼 예정. 읽으면서 블로그에 내용을 정리해보려 하는데, 업로드 순서는 책과는 다르게 중구난방이 될 수도 있다. 당장 하드웨어 설계에 필요한 부분부터 읽을 것이기 때문에, 양해를 부탁드리는 바이다.
내가 회사에서 하던 디지털 회로는 주로 filter 기반의 shallow ISP로 앞으로 연구 과정에서 설계해야 할 프로세서와는 결이 많이 다르다. 내가 설계한 IP로 입력되는 데이터는 sync 신호에 맞춰서 들어오기 때문에, 프로토콜에 맞춰서 잘(?) 설계만 하면 됐었다. 그래서 5년의 디지털 회로 설계 경력이 무색하게도 이런 scratch 수준의 SoC 설계는 처음이라 해도 무방하다. 특히 이렇게 데이터 플로우가 DRAM과 같은 메인 메모리를 거쳐야 하는 경우의 설계를 해보지 않아 초장부터 막막함을 많이 느끼고 있다.
어둠 속의 한 줄기 빛처럼 나를 구원해 줄 메시아. Efficient Processing of Deep Neural Networks. 이 책에 분명 길이 있을 것이고, 나처럼 어려움을 겪는 누군가에게도 이 포스팅이 길잡이가 될 수 있기를 바라며 서문을 연다.
Ch 4. Kernel computation
딥 신경망 네트워크 (DNN)를 학습시키거나 특정 응용을 위한 목적으로 추론하는 과정에서, 빠른 연산을 위해 GPU/CPU 혹은 ASIC/FPGA 등의 H/W accelerator를 사용한다. 이때, 가속을 위해 병렬로 연산을 처리하는데, 병렬로 처리되는 주된 산술연산이 MAC (multiplication + accumulation)이다. 이러한 산술연산을 처리하는 ALU (Arithmetic logic units)가 중앙으로부터 받은 명령어에 따라 구동되며, 메모리의 hierarchy에 따라 데이터가 fetch 되고, ALU 간 직접적인 통신은 하지 않는 구조를 temporal architecture라고 한다.
이와 반대로, ALU간 통신이 가능하며, dataflow processing을 지원하는 구조를 spatial architecture라고 한다. 이러한 구조에서는 각 ALU가 개별적인 control logic을 가지고 있으며, scratchpad나 register file이라고 부르는 로컬 메모리를 가지고 있다. 보통 이러한 구조의 로컬 메모리를 갖는 ALU를 PE (Processing engine, element)라고 부른다. Spatial architecture는 주로 ASIC/FPGA 기반의 DNN acclerator 구조에서 많이 사용된다.
Parallel compute paradigms에 따른 디자인 전략
- - Temporal architecture
: Throughput을 늘리기 위해 multiplication을 줄이는 방법, 연산의 순서를 바꿔서 메모리 서브시스템을 효율적으로 사용하는 방법 등 - - Spatial architecture
: Dataflow를 적절히 구성하여, 적은 양의 메모리로 데이터 재사용성을 늘리고, 에너지 소비량을 절약하는 방법 등
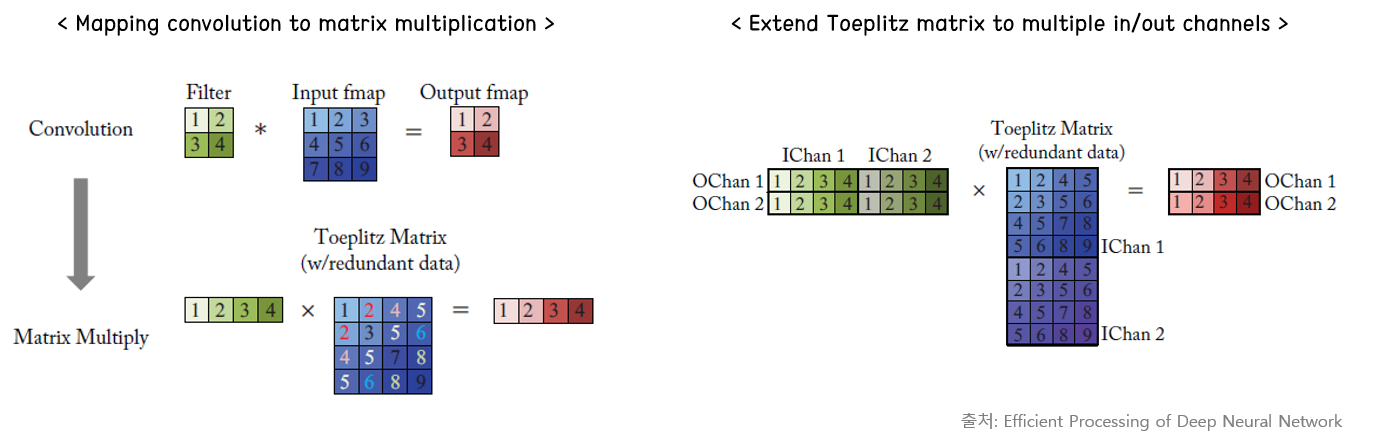
Matrix multiplication with toeplitz
테플리츠 행렬이란, 대각 상수(diagonal-constant) 행렬로, 대각선 위의 성분이 같은 행렬이다. Convolution 연산을 matrix multplication으로 변환하여 병렬로 처리하기 위해 사용된다.

아래와 같이 filter와 입력 feature map을 펼쳐서 matrix form으로 변환하며, 입력 feature map에는 중복되는 데이터가 발생하므로 저장 공간이 늘어나고, 비효율적인 메모리 접근 패턴이 발생할 수 있다. 그래서 일반적인 accelerator에서 사용하기보다는 GPU/CPU 등에서 H/W 병렬 처리 과정에서 주로 사용되는 듯하다. 오른쪽 그림은 channel 방향으로 차원을 확장했을 경우의 연산을 나타낸 것이다. 각 입력 channel 마다 같은 크기의 출력 channel의 feature map이 얻어지는 것을 확인할 수 있다.
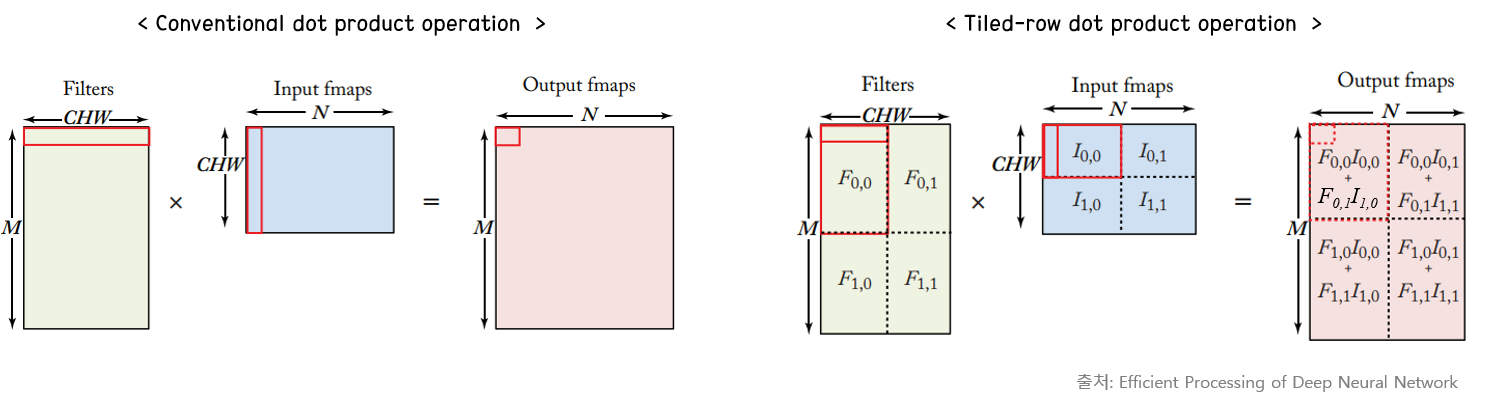
Tiling for optimizing performance
Tiling은 FPGA나 H/W Accelerator 논문에서 심심찮게 볼 수 있었던 내용이다. Tile 형태로 feature map을 쪼개 놓는다면, 한 번에 데이터를 읽어서 재사용할 수 있는 reusability distance가 줄어든다. 본 예시에서는 Matrix multiplication을 하는 경우 dot product 연산에서 tiling을 적용했지만, 이전에 찾아본 논문에서는 동일한 장점을 살리기 위해 convolution 연산에 해당 방법을 적용했다. 책에서는 tiling을 할 때에는 메모리의 hierarchy를 잘 나눠 놓아야 메모리 재사용성을 극대화할 수 있다고 설명하고 있다. 오른쪽 아래 그림처럼 Tile 형태로 구획을 나눠 놓는다면, local buffer 사이즈의 제한으로 인해 DRAM에 재접근을 해야 하는 상황을 방지할 수 있다.
Computation transform optimizations
보통 multiplication이 전력 소모 측면에서 매우 비싼 연산이므로, 특정한 형태로 변환하여 multiplication의 횟수를 줄이는 방법을 소개한다.
1. Gauss complex multiplication transform
일반적인 복소수 연산에서 곱셈은 4번, 덧셈이 3번 필요하다. 뺄셈의 경우에는 2의 보수로 bit 반전 후 더해주는 것과 동일하므로 덧셈과 비용 차이가 없다고 가정한다. 이를 아래와 같이 중간 매개변수 k1, k2, k3로 값을 변환하고 실수와 허수 파트를 각각 구하면, 덧셈이 2번 늘어나지만 곱셈을 1번 줄일 수 있다. adder의 경우 multiplication과 비교해서 들어가는 비용이 저렴하므로, 충분히 납득이 가는 방식이다.

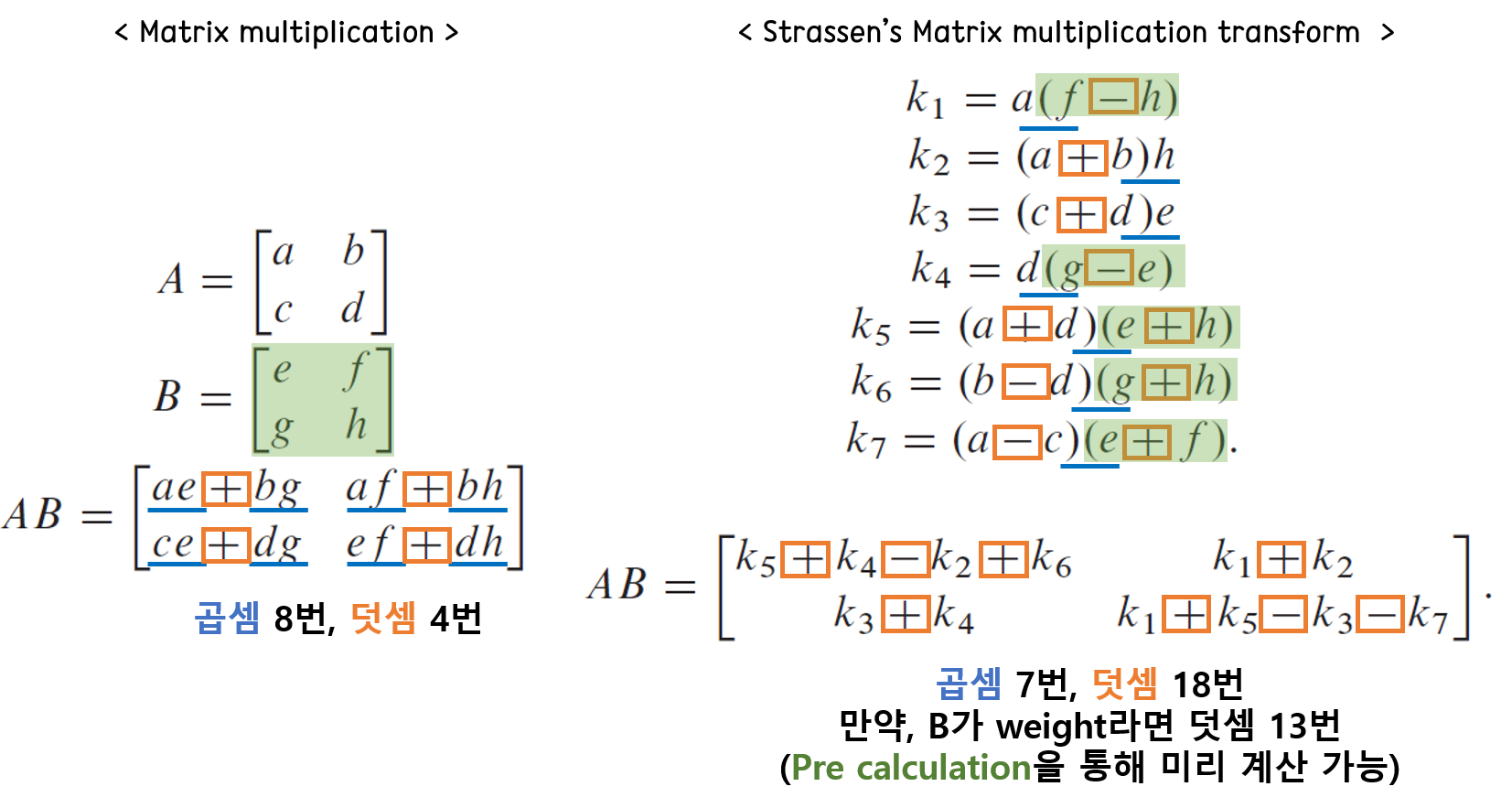
2. Strassens's matrix multiplication transform
슈트라센 알고리즘은 독일의 수학자 폴커 슈트라센이 개발한 행렬 곱셈 알고리즘이다. nxn 크기의 정사각행렬 간의 곱셈에 O(n3)의 시간이 소요되는 반면, 이 알고리즘을 사용하면 O(n2.807)로 줄일 수 있다고 알려져 있다. 아래와 같이 일반적인 2x2 행렬의 곱셈에서 각 원소는 8번의 곱셈과 4번의 덧셈이 필요하다. 그러나 이 알고리즘을 사용하면, 곱셈을 7번, 덧셈을 18번으로 만들 수 있다. 여기서 만약 B가 weight라면 이미 알고 있는 값이므로, 사전 작업을 통해 연산 후 메모리에 넣는다고 하면, 곱셈 7번, 덧셈 13번으로 더욱 효과적으로 곱셈을 줄일 수 있다. 아래의 그림에서 초록색 음영으로 표시한 부분이 사전 작업을 통해 줄일 수 있는 weight의 연산 부분이다.
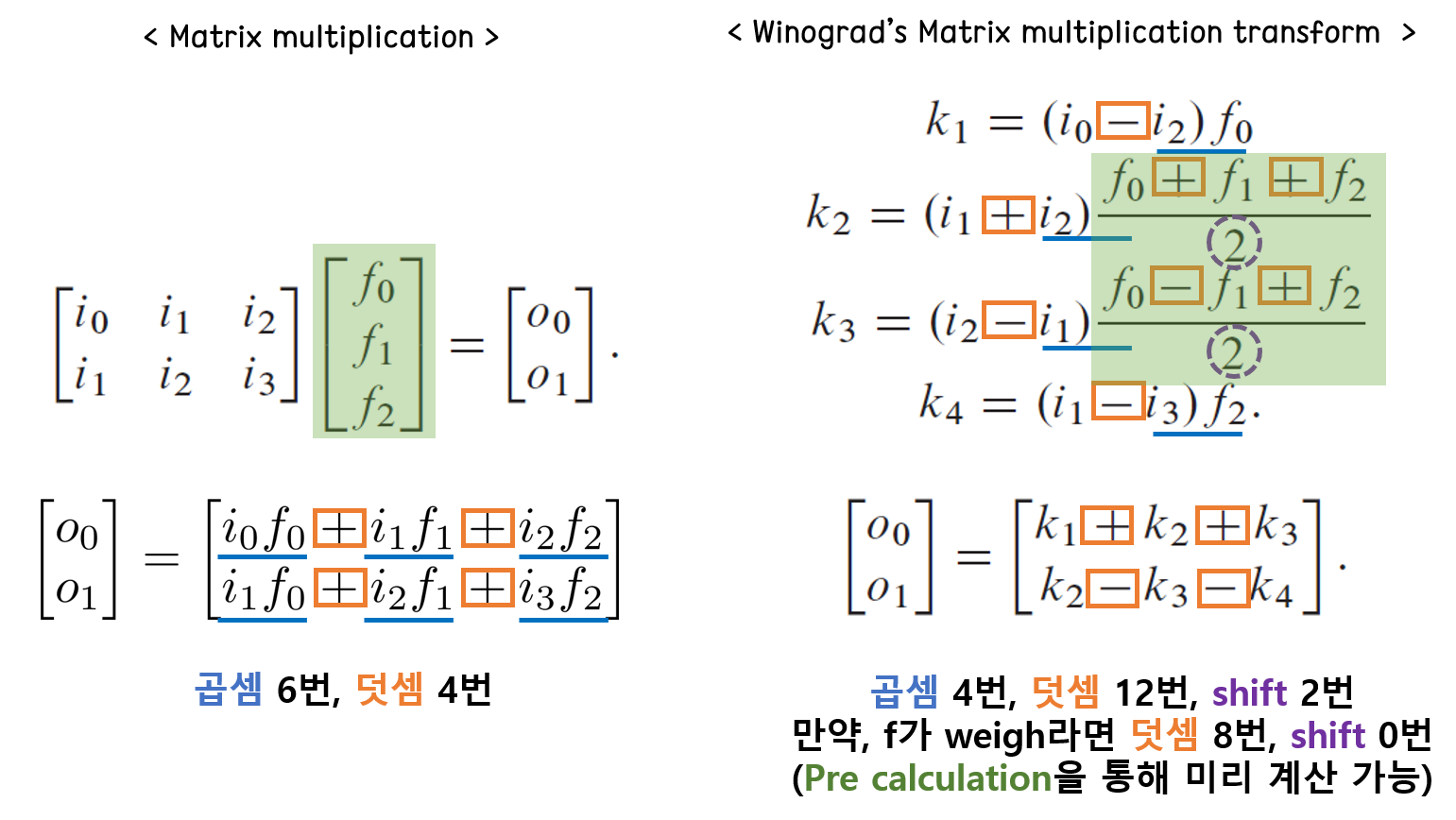
3. Winograd transform
위노그라드 알고리즘은 슈트라센 알고리즘을 변형한 것으로, 점근적으로 슈트라센 알고리즘과 동일한 복잡도를 지니지만 덧셈의 횟수를 더 줄이는 방법이다. 아래와 같이 입력 feature map이 2x3, filter의 크기가 3x1인 Matmul을 한다고 가정하면, Winograd 변환을 사용하여 곱셈을 6번에서 4번으로 줄일 수 있다. 여기에 앞서 슈트라센 알고리즘과 동일하게 weight를 미리 연산해서 메모리에 담는다면, 덧셈을 12번에서 8번으로, shift를 2번에서 0번으로 줄일 수 있다. 다만 이러한 연산이 만능인 것은 아니고, convolution 연산을 matrix 형태로 변환하는 과정에서 저장 공간이 많이 필요하게 되므로, 이러한 trade-off를 잘 고려해서 아키텍처를 결정해야 한다.
입력 feature map을 4x4로, filter 크기를 3x3이라고 가정한 형태의 일반적인 위노그라드 변환 폼은 아래와 같다. 처음 책에서 이 부분을 봤을 때, i와 f의 사이즈를 명시해주지 않아 행렬 곱으로 계산이 되지 않아 당황했었다. 다른 논문을 찾아보니, 2D 형태로 위노그라드 변환할 때의 각 변환 행렬을 나타낸 것임을 알 수 있었다. i는 입력 activation, f는 filter, Y는 출력 activation이라고 보면 되고, G, B, A 등은 변환 행렬이다.
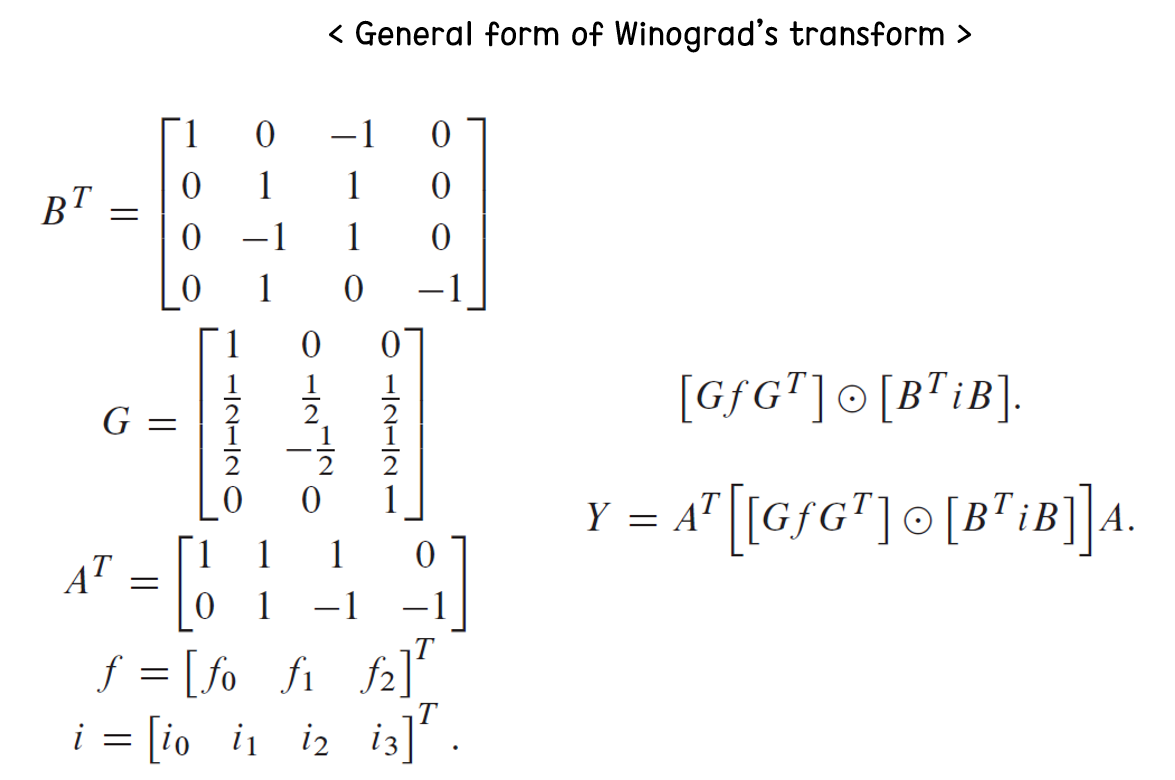
입력 feature map과 filter size를 1D(F(m,r))에서 2D(F(mxm, rxr)) 형태로 확장하면 아래 수식과 같고, 위의 각 변환 행렬을 1D 형태 form으로 나타내면 위의 수식도 행렬 곱으로 연산이 잘 됨을 확인할 수 있다. 다만, 여기서는 2D 형태 form으로 나타내고, i와 f는 마치 1D인 것처럼 표현하여 헷갈린 것이다.

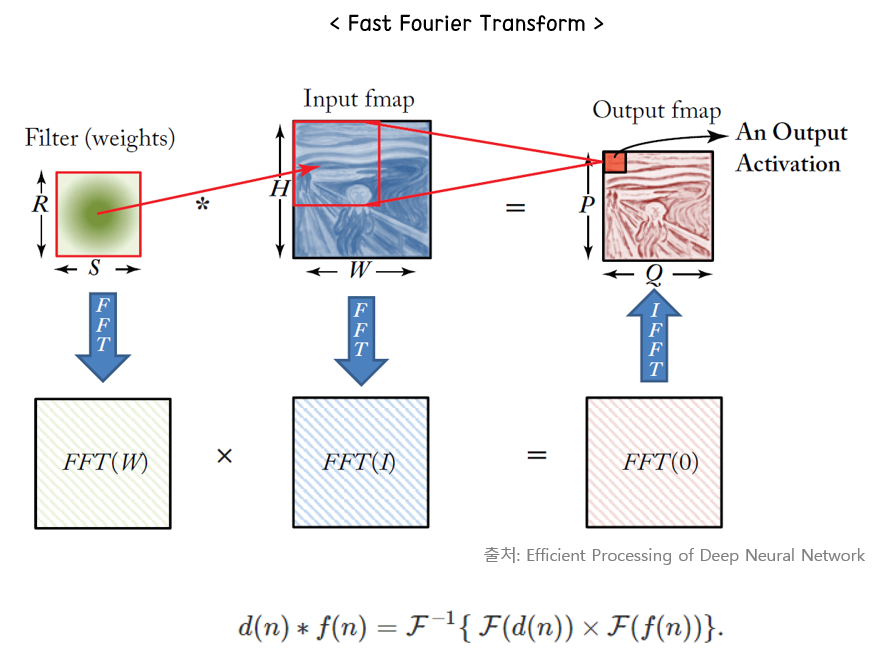
4. Fast fourier transform
여러분이 잘 알고 있는 그 퓨리에 변환 맞다. 컨볼루션 연산을 주파수 대역으로 옮기면 곱의 형태로 바뀐다는 사실은 잘 알고 있을 것이다. 이러한 특성을 활용하여 주파수 대역으로 변환하여 각 map을 곱하고, 다시 역변환을 취해주는 형태로 구현된다. 다만 변환할 때, 출력 feature map의 크기와 동일하게 입력 feature map과 filter를 reshape 하는 과정에서 메모리의 사용량이 늘어날 수 있다는 단점이 있다.
마지막으로, 책에서는 각 transform을 적용할 때는 reusability와 low complexity를 고려하여 선택해야 한다고 명시하고 있다. Ch. 4에서는 temporal architecture에 사용되는 다양한 디자인 테크닉에 대해서 다뤘다면은 Ch. 5에서는 Dataflow를 비롯하여 spatial architecture에 필요한 다양한 내용들을 다루고 있다. 다음 시간에는 DNN Accelerator의 핵심이라고 할 수 있는 Ch. 5 Design DNN Accelerators를 본격적으로 살펴볼 것이다.
'머신러닝 & 딥러닝' 카테고리의 다른 글
| [후기] 가속기 프로그래밍 겨울캠프에 다녀오다. (4) | 2024.02.27 |
|---|---|
| [스터디 후기] 부스트코스 코칭스터디 - 데이터 사이언스 프로젝트 2024 (0) | 2024.02.26 |
| [책] Efficient Processing of Deep Neural Network - Ch5. Designing DNN Accelerators (1) (0) | 2023.03.05 |
| [PyTorch] Distributed DataParallel로 Multi GPU 연산하기 (4) | 2023.01.18 |
| [Kaggle] Horses or humans dataset으로 이미지 분류하기 (0) | 2022.10.23 |