
티스토리 뷰

🎈 여는 글
지난 2월 20일부터 24일까지 4박 5일 기간 동안 가속기 프로그래밍 겨울캠프에 다녀왔다. 평소 연구를 하면서 cuda 프로그래밍 및 GPU 아키텍처에 관해 갈증이 많았던 터라 모집 공지를 보자마자 꼭 참가해야겠다고 생각했다. 다만 수강료가 큰 부담이었는데, 랩에서 연구원으로 등록된 학생들은 연구비 지원을 받을 수 있었지만 나와 같이 회사에서 온 사람들은 과제를 할 수가 없기 때문에 연구원으로 등록할 수가 없고, 당연히 연구비 지원도 받을 수 없었다. 교수님께서는 지원해 줄 수 있는 방법이 없으시다며, 회사에서 교육 참가에 따른 비용을 지원해 줄 수 있는지 문의해 보라고 하셨다. 당연히 그런 것이 될 리가 없었고... 결국 나는 사비로 다녀왔다.
🎈 가속기 프로그래밍 겨울캠프
이 캠프는 서울대학교 이재진 교수님 연구실 (천둥 Lab)에서 여름과 겨울, 1년에 2회 진행하는 4박 5일 기간의 캠프이다. GPU를 이용한 병렬 프로그래밍 수업이 컴퓨터 공학과 및 데이터 사이언스 공학과에 개설되는 것으로 알고 있으며, 이 한학기 분량의 수업을 5일로 압축해서 진행된다고 생각하면 된다. 나는 이미 수료를 한 상황이었기 때문에 청강으로 들을 수밖에 없었는데, 청강은 효율이 절대 나올 수 없다고 생각해서 과감하게 질렀다. 등록은 기본반과 고급반으로 나뉘어 있으며, 고급반은 기본적인 내용과 더불어 multi GPU나 tensor core 사용 등의 심화 내용을 다룬다. 만약 본인이 cuda 프로그래밍에 대한 기본적인 부분을 숙지하고 있다면, 고급반을 바로 듣는 것을 추천한다. 나의 경우에는 관련 경험 및 지식이 전무하다시피 했기 때문에 기본반을 수강하였다.
수업은 서울대학교 시흥캠퍼스 교육동에서 진행되었으며, 1시간 반 분량의 수업이 매일 2~3회 있었고, 그 외 7시부터 9시까지의 실습 시간이 주어졌다. 중간에 쉬는 시간이 30분씩으로 충분히 주어졌기에 모자란 실습 분량을 채울 수 있었으며, 전체 수업은 책 한권 가량의 이론 및 실습수업으로 알차게 구성되었다. 수업이나 실습 및 프로젝트 중에 궁금한 점이 있으면 언제든지 조교님에게 질문을 할 수 있었고, 이 점이 이 캠프의 가장 큰 매리트라고 생각이 들었다. 강사님이나 조교님의 병렬 프로그래밍에 대한 내공이 상당했으며, 프로젝트에서 막히는 부분을 혈 자리를 풀듯이 시원하게 해소시켜 주셨다.
숙소인 연수동은 새로 지어진 건물이라 그런지 매우 깔끔했고, 웬만한 비즈니스호텔 정도의 룸 컨디션을 기대해도 좋다. 그리고 장점이자 단점으로 서울대학교 시흥캠퍼스는 번화가에서 다소 외진 곳에 자리 잡고 있기에, 오로지 학습에만 신경 쓸 수 있는 환경(?)이 저절로 갖춰진다고 볼 수 있다. 나처럼 혼자 온 것이 아닌 랩에서 다 같이 온 케이스가 많았는데, 다들 첫날은 주변 술집 등에서 한 잔 하면서 회포를 풀지 않을까 했지만 의외로 그런 것 같지는 않아 보였다. 4박 5일 기간 동안 프로젝트가 진행되는데, 1등 상품이 무려 아이패드였기 때문에 다들 첫날부터 달리는 눈치였다. 과제 주제는 주어진 CPU에서 돌도록 만들어진 딥러닝 네트워크를 GPU로 포팅해서, 배운 내용을 토대로 최적화 및 병렬화를 수행하는 것이었다. 초당 throughput이 높은 순으로 수상이 되며, 1등부터 3등까지는 상품까지도 득템 할 수 있는 일종의 동기부여 장치라고 볼 수 있었다.
나의 경우에는 무엇보다 식사가 굉장히 마음에 들었는데, 5일 만에 3kg이 쪘다는 사실에서 제공되는 식사의 퀄리티를 짐작할 수 있을 것이라고 본다. 삼시 세 끼를 꼬박 챙겨 먹기를 추천한다.
🎈 배운 것들에 대한 단편적인 나열
4박 5일 캠프를 통해서 cuda 병렬 프로그래밍의 모든 것을 배웠다고 보기에는 어렵지만, 아래와 같은 내용에 대한 전반적인 지식을 학습할 수 있었다. 그리고 cuda 코드나 GPU 병렬 프로그래밍 코드를 외계어가 아닌 외국어 정도의 느낌으로는 접근할 수 있는 기본 소양을 갖추게 되었다고 생각한다. 이 캠프에 참가하게 된다면 아래 망라한 내용들에 대해 기본 지식을 습득할 수 있으며, 대규모 컴퓨팅이나 병렬 처리 쪽에 관심이 많은 사람이라면 앞으로의 공부 및 연구에 큰 도움이 되는 캠프라고 자신한다.
- 병렬 처리 프로그래밍에 대한 기본적인 이해
- 디펜던스 (디펜던시 아님! - 교수님께서 디펜던시는 근본이 없는 표현이라고 하심)
: 작업 간의 디펜던스가 발생하지 않도록 데이터 처리 순서를 조정해야 한다.
- 암달의 법칙
: 병렬화가 되지 않는 부분에 의해 전체적인 성능이 좌우된다.
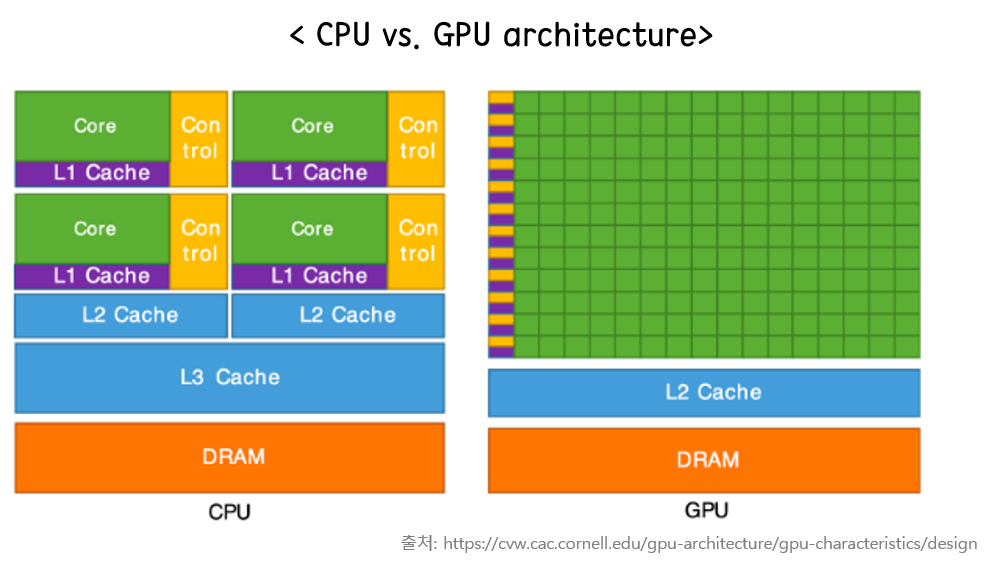
- CPU(호스트)와 GPU(디바이스) 구조의 차이
1) GPU는 왜 코어가 많고, 스레드가 많을수록 성능이 더 높아지는지
2) CPU는 스레드가 코어 수에 맞게 할당되어야 성능이 더 좋은지
- 커널의 사용
: 스레드의 인덱스를 통해서 병렬로 연산하도록 프로그래밍이 가능하다.
// 기본적인 vector add 병렬 연산
__global__ void vecAdd(int* _a, int* _b, int* _c) {
idx = blockDim.x * blockIdx.x + thresadIdx.x
_c[idx] = _a[idx] + _b[idx];
}
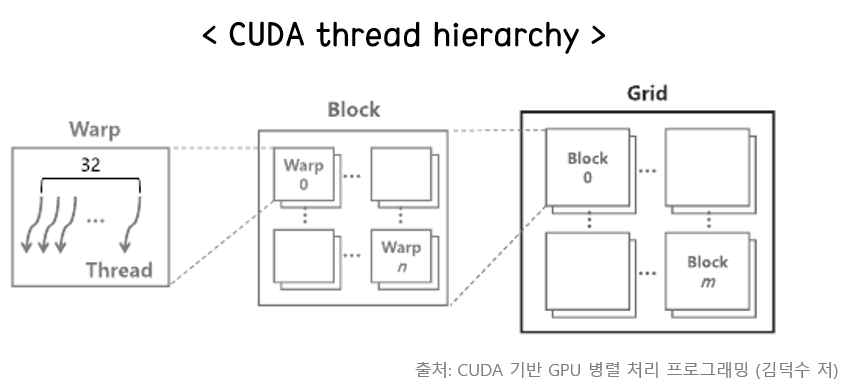
- 스레드는 32개 단위로 묶이고, 이를 warp라고 한다.
- GPU는 다수의 streaming multi-processor(SM)로 구성되어 있으며, 내부 스레드의 계층이 grid -> block -> thread 순으로 구성된다.
- grid라는 단위 안에 여러 block이 존재하며, block은 최대 1024개의 스레드로 구성된다.
- grid dimension과 block dimension은 최대 3차원까지 설정할 수 있다.
- SM 내에 각 precision 별 연산 unit과 fetch/decode를 수행할 수 있는 control block이 위치한다. 또한 공유 메모리, L1 cache, register 등이 존재한다.
- cuda 병렬 프로그래밍을 위한 기본적인 스텝은 아래와 같다.
1) cudaMalloc으로 GPU 메모리 공간을 할당한다.
2) cudaMemcpy로 CPU(호스트) -> GPU(디바이스)로 데이터를 전달한다.
3) 커널 함수를 통해 병렬 연산을 수행한다.
4) cudaMemcpy로 GPU(디바이스) -> CPU(호스트)로 데이터를 전달한다.
5) cudaFree로 사용을 마친 메모리를 해제한다.
- pinned memory를 통해 CPU 상의 데이터를 디바이스로 더 빠르게 전송할 수 있다.
: 일반적으로 pinned memory로 선언하지 않으면, paged memory가 되어 CPU/GPU 간에 가상화된 메모리가 할당된다.
- 공유 메모리 사용
: GPU 내의 shared memory는 보통 L1 cache에 저장되므로, 더욱 빠르게 데이터에 접근할 수 있다.
// 공유 메모리의 static allocation
__global__ void kernel(void)
{
__shared__ int shared_mem[512];
}
// 공유 메모리의 dynamic allocation
extern __shared__ int dynamic_shared_mem[];: GPU에 올라가 있는 데이터를 스레드에서 처리할 수 있는 양으로 인덱스를 맞춰 준 다음 (ex. Tiling), 공유 메모리를 통해 처리하도록 만들면 더 빠른 연산이 가능하다.
#define TILE_WIDTH 16
__global__ void MatrixMulKernel(float *d_M, float *d_N, float *d_P, int Width) {
__shared__ float Mds[TILE_WIDTH][TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x; int by = blockIdx.y;
int tx = threadIdx.x; int ty = threadIdx.y;
// 각 스레드가 결과 매트릭스의 요소를 계산하는데 필요한 행과 열을 식별합니다.
int Row = by * TILE_WIDTH + ty;
int Col = bx * TILE_WIDTH + tx;
float Pvalue = 0;
// 타일을 통해 반복하며 각 타일에 대해 Pvalue를 누적합니다.
for (int m = 0; m < Width/TILE_WIDTH; ++m) {
// M과 N의 타일을 공유 메모리에 로드합니다.
Mds[ty][tx] = d_M[Row*Width + (m*TILE_WIDTH + tx)];
Nds[ty][tx] = d_N[(m*TILE_WIDTH + ty)*Width + Col];
__syncthreads();
// 타일에 대해 계산을 수행합니다.
for (int k = 0; k < TILE_WIDTH; ++k) {
Pvalue += Mds[ty][k] * Nds[k][tx];
}
__syncthreads();
}
d_P[Row*Width + Col] = Pvalue;
}- 블록 안에서는 서로 공유메모리에 접근이 가능하지만, 서로 다른 블럭 사이에서는 공유 메모리 접근이 불가능하다.
- Reduce
: 연산 속도를 높이기 위해 reduce 연산을 사용하면 공유 메모리를 효과적으로 활용할 수 있다. reduce 연산 후, 연산을 다 처리하지 못하고 남은 경우, CPU에서 처리하거나 kernel을 남은 연산을 처리할 수 있을 만큼 더 수행하는 식으로 프로그래머가 코드를 작성해야 한다.
- 메모리 접근 패턴을 고려하면, 성능을 더 높일 수 있다. 이는 memory coalescing이라고 하는데 cache와 마찬가지로 공유 메모리의 접근도 locality를 고려해야 한다. 즉, 데이터를 읽거나 쓰기 위한 인덱스를 만드는 과정에서도 메모리가 연속적으로 데이터를 불러올 수 있도록 하는 것이 좋다. 이는 데이터 타입 자체를 vector로 지정해서 구현할 수도 있다.
- blocked vs. non-blocked를 잘 고려하여 동기화를 해줘야 한다.
- async 구조의 함수를 사용하여 제어하기 위해서는 동기화를 고려해야 한다.
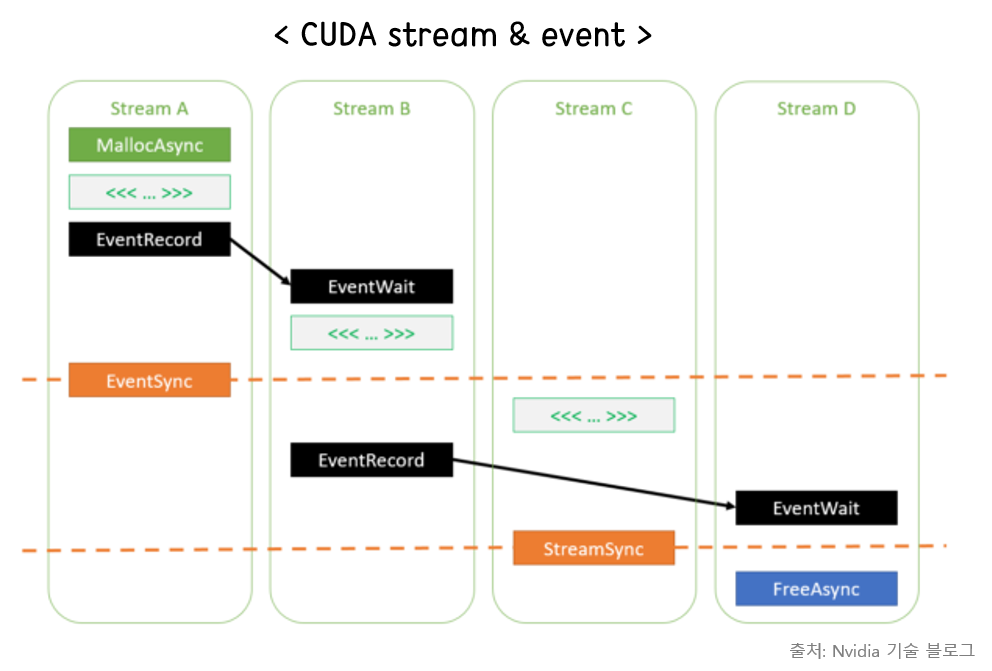
- stream과 event를 통해 비동기 동작에서 효율적인 스케줄링이 가능하다.
1) 더블/트리플 버퍼링의 구현을 통해 동시에 여러 stream으로 커널이 처리되게 만들 수 있다.
2) stream은 커널이 수행되는 lane이라고 이해하면 되며, event는 수행되는 커널이 기다리거나 시작되는 시점을 명시해 주는 마커이다.
- TOPS, throughput을 보고, GPU가 최대로 낼 수 있는 peak performance 대비 현재 성능이 어느 정도 되는지 확인해 보면서 최적화를 진행해야 한다.
- Nightsystems, Nightcompute와 같은 cuda 프로파일링 툴을 통해서 어떤 부분이 병목을 일으키는지 확인해야 한다.
1) memory bound vs. compute bound
2) roof line model을 보고, 어떻게 성능을 더 올릴 수 있을지 생각해야 한다.
- cuda 함수는 error가 발생할 경우 에러 코드를 반환하고, 정상적으로 돌았을 경우 cudaSuccess를 반환한다. 이를 체크하기 위해 매크로 함수로 error 발생 여부를 확인해야 디버깅이 용이해진다.
// Error check 매크로
#define CHECK_CUDA(call) \
do { \
cudaError_t status_ = call; \
if (status_ != cudaSuccess) { \
fprintf(stderr, "CUDA error (%s:%d): %s:%s\n", __FILE__, __LINE__, \
cudaGetErrorName(status_), cudaGetErrorString(status_)); \
exit(EXIT_FAILURE); \
} \
} while (0)
// 사용 예시
int main() {
int count;
CHECK_CUDA(cudaGetDeviceCount(&count));
printf("Number of devices: %d\n", count);
}
🎈 마무리하며...
LLM을 필두로 한 AI의 발전으로 인해 HBM과 같은 대용량 메모리와 수백~수천 개의 GPU를 처리해야 하는 슈퍼 컴퓨팅 기술은 날로 중요해질 것이다. 이번 캠프를 통해 cuda 병렬 프로그래밍에 대한 기본적인 소양을 닦았으니, 지금 하고 있는 연구에 배운 지식을 어떻게 잘 써먹을 수 있을지 고민해 봐야겠다. 마지막으로 수료증을 인증하고 글을 마무리 지으려 한다.

'머신러닝 & 딥러닝' 카테고리의 다른 글
| [스터디 후기] 부스트코스 코칭스터디 - 데이터 사이언스 프로젝트 2024 (0) | 2024.02.26 |
|---|---|
| [책] Efficient Processing of Deep Neural Network - Ch5. Designing DNN Accelerators (1) (0) | 2023.03.05 |
| [PyTorch] Distributed DataParallel로 Multi GPU 연산하기 (4) | 2023.01.18 |
| [책] Efficient Processing of Deep Neural Network - Ch4. Kernel Computation (2) | 2023.01.17 |
| [Kaggle] Horses or humans dataset으로 이미지 분류하기 (0) | 2022.10.23 |