
티스토리 뷰
[책] Efficient Processing of Deep Neural Network - Ch5. Designing DNN Accelerators (1)
DreamSailor 2023. 3. 5. 23:05
좋은 DNN Accelerator의 요건은 뭘까?
낮은 전력 소모와 적은 양의 메모리를 사용하면서도 적은 latency와 높은 throughput을 가지며 병렬화가 잘 되어 높은 수준의 Processing Element (PE) Utilization을 확보해야 한다. 어떻게 이러한 목표를 달성할 수 있을지 생각해 보면 아주 보편적인 접근 방법이 도출된다. 데이터의 재사용성을 높이고, 불필요한 연산은 하지 않고 넘긴다. (Sparsity를 최대한 활용한다.) 데이터를 처리하는 순서를 잘(?) 배치한다. 본 책에서는 기존의 연구 및 양산된 제품들이 앞서 서술한 목표를 달성하기 위해 고안한 아이디어와 방법에 대해서 친절하게 설명하고 있다.
병렬로 배치되어 있는 PE를 데이터가 지나가면서, 여러 번의 MAC (Multiplication and Accumulation) 연산을 수행하게 되는데, 이때 최대한 재사용을 높이는 방향으로 처리를 할 수 있도록 스케줄링을 해야 한다.
예를 들자면, 이런 식이다.
- 동일한 입력 feature map을 출력 activation의 차원 크기(M) 만큼 재사용한다. 즉, 출력 feature map의 차원 수인 M회 동안 한 번 off-chip으로 부터 읽어온 입력이 재사용된다..
- 입력 feature map의 batch를 처리하는 동안, 동일한 filter를 입력 차원의 batch 수만큼 재사용한다. 일반적인 inference 목적의 가속기보다는 training을 함께 지원하는 NPU 계열의 가속기에 어울리는 컨셉이다.
- CNN 연산에서는 각 weight는 출력 activation의 크기인 P x Q 만큼 재사용되고, 입력 activation은 filter의 크기인 R x S 만큼 재사용된다고 볼 수 있다.
Latency를 최소화하면서 throughput을 늘리기 위하여, 한 사이클에 C(채널) x R x S (커널 크기)의 연산이 완료되어 출력 activation을 구할 수 있으면 가장 좋다. 이를 구현하기 위해 PE를 이동하면서 누적된 partial sum을 adder tree 형태로 구현하여, 저장 공간을 최소화하면서 상기의 목적을 달성하는 구조를 가져가기도 한다. 물론 이러한 아키텍처가 항상 만능이라고 볼 수는 없고, 오히려 adder 다발이 설계의 크기나 타이밍 측면에서 bottle-neck이 될 수도 있으니 사전에 충분한 고려가 필요하다.
특정한 DNN 모델이 주어졌을 때, 높은 성능을 유지하면서 에너지 소비 효율을 올리는 것은 매우 중요한 일이다. 이러한 목표를 달성하기 위해서는 최적의 mapping을 구하는 일이 수반되어야 한다. 여기서 최적의 mapping이란, (1) MAC 연산의 실행 순서를 결정하는 것과 (2) 데이터를 어떻게 이동시키고, 각 메모리의 계층에 따른 연산을 어떻게 수행할 것인지를 찾는 것을 의미한다. 예를 들어, 동일한 PE가 순차적인 입력을 받아 MAC 연산을 수행할지, 아니면 여러 PE를 사용해 동시에 계산을 진행할지 등도 최적의 설계를 위하여 결정되어야 할 요소이다.
특히, DNN 가속기에서는 in/out activation과 weight와 같은 각 요소들이 PE에 머무르면서 연산을 수행할 것인지, 아니면 각 PE를 이동해 가면서 누적합을 업데이트 해갈 것인지에 따라서 다양한 경우의 수가 발생한다. 이를 "dataflow"를 결정한다고 하며, 이에 따라 하드웨어 구조가 결정되므로 데이터의 흐름을 어떻게 가져갈 것인지가 설계의 주안점이 된다.
Temporal reuse와 spatial reuse
데이터의 재사용을 고려할 때, 시간적으로 일단 읽어온 데이터를 연속적으로 사용할 수 있도록 구성하는 것이 temporal reuse이고, 데이터를 여러 연산 유닛에서 동시에 처리하도록 구현하는 것이 spatial reuse이다. 즉, 시간 혹은 공간을 축으로 데이터를 재사용하여 상위의 메모리 (ex. off-chip DRAM)의 접근을 최소화하고,, 중간 계층의 메모리 (ex. on-chip cache)를 활용하여 에너지 소모를 줄이는 것이다.
이 세계가 언제나 그렇지만 좋아지는 게 있으면 나빠지는 게 있는 법. Spatial reusability를 높이기 위해 무턱대고 각 PE와 memory를 multi-casting으로 연결하다 보면, 라우팅도 복잡해지고 메모리 컨트롤도 어려워진다.
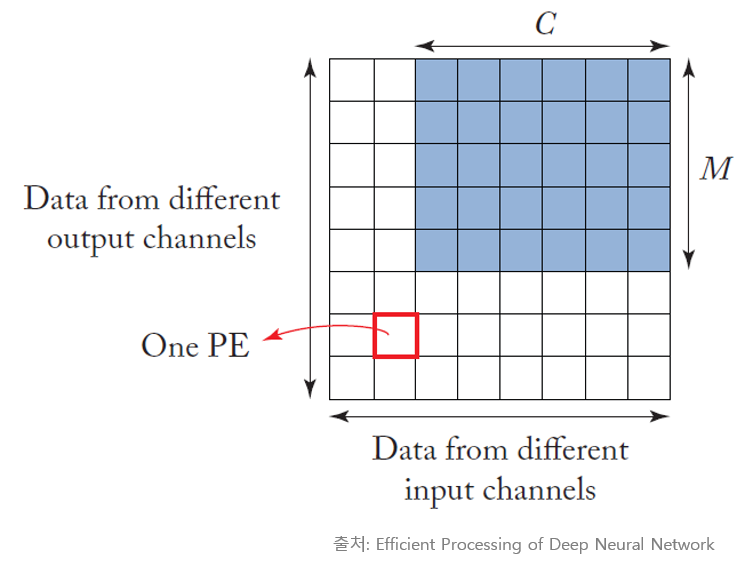
Data reuse distance를 줄이기 위해 대표적으로 사용할 수 있는 방법이 Tiling이다. 이 방법은 지난 포스팅에서도 간단히 소개한 바 있지만, 한 번에 처리할 데이터의 양을 Tile의 크기로 제한하여 한정된 하드웨어 자원을 효율적으로 사용할 수 있도록 만들어 준다.
🔽 Tiling에 관한 지난 포스팅
https://dreamsailor.tistory.com/45
[책] Efficient Processing of Deep Neural Network - Ch4. Kernel Computation
들어가며 이 책은 딥러닝 가속기를 연구하는 사람이나 이 분야를 업으로 삼고 있는 사람들에게는 바이블과 같은 책이다. 나도 아직 끝까지 다 읽지는 못했지만 방학(이라 읽고 연구 집중 기간이
dreamsailor.tistory.com
많은 PE를 병렬적으로 배치시키고, 동일한 cycle에 많은 양의 데이터를 처리할 수 있도록 하는 것은 하드웨어 가속의 기본적인 컨셉이다. 그러나 단순히 연산 유닛을 많이 둔다고 해서 성능이 그 숫자에 비례해서 증가하는 것은 아니다. 각 layer마다 필요로 하는 연산량이 항상 동일한 것이 아니므로 peak bandwidth를 갖는 layer를 기준으로 코어를 배치하면 다른 layer에서는 PE utilization이 떨어지는 문제가 발생하기 때문이다. 이를 스타크래프트로 비유하자면, 베럭의 개수를 늘려놓고 미네랄과 가스가 부족해서 병력을 뽑지 못해 땅 덩어리와 자원만 낭비한 꼴이 되는 것과 같다.
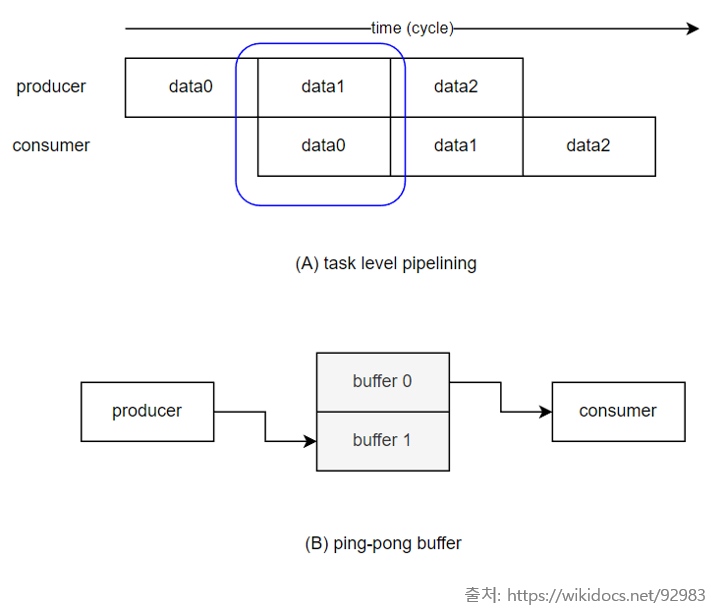
보통 다수의 PE를 병렬로 배치하여 공간적인 재사용성을 높이는 형태로 에너지 효율을 높이면서 하드웨어 가속을 구현하고, latency 측면에서 이득을 볼 수 있도록 double buffering 기술을 적용하여 데이터를 prefetch 하여 바로 연산을 할 수 있게 한다. double buffer란 단어 뜻 그대로 shadow buffer와 front buffer를 이중으로 두고, 코어가 현재 값을 처리할 때는 front buffer에서 데이터를 읽고, 다음 데이터를 바로 불러올 수 있도록 shadow buffer에 off-chip의 데이터를 읽어오는 버퍼 구조를 말한다. shadow buffer와 front buffer는 역할이 계속 swap 되기 때문에 ping-pong buffer라고도 불린다.
일반적으로 그래픽스 쪽에서도 디스플레이로 출력하는 frame buffer를 double buffering으로 구현하여, 중간에 끊기는 영상이 나오지 않도록 하는 것으로 알고 있다. 회사에 재직중일 때에도 이 컨셉을 사용한 적이 있었는데, 이중 클럭 도메인이 사용된 칩에서 register bank를 double buffering으로 구현하여 CDC(Clock domain crossing) violation에 강건한 구조를 가져갈 수 있도록 하였다. 이는 register bank의 read/write를 위한 clock의 주파수와 이 register를 사용하는 모듈의 clock 주파수가 달랐기 때문에 발생할 수 있는 문제를 buffer를 이중으로 구현하여 서로 격리시키는 형태로 해결책을 낸 것이었다.
다음 포스팅에서는 챕터 5장의 꽃이라고 볼 수 있는 "Dataflow"에서 다뤄볼 예정이다. 딥러닝 가속기의 대표적인 chip인 MIT의 Eyeriss v1, Google의 TPU, NVDIA의 NVDLA 등의 아키텍처를 함께 보면서 dataflow의 개념에 대해 깊이 이해하는 것을 목표로 내용을 정리해보려고 한다.
'머신러닝 & 딥러닝' 카테고리의 다른 글
| [후기] 가속기 프로그래밍 겨울캠프에 다녀오다. (4) | 2024.02.27 |
|---|---|
| [스터디 후기] 부스트코스 코칭스터디 - 데이터 사이언스 프로젝트 2024 (0) | 2024.02.26 |
| [PyTorch] Distributed DataParallel로 Multi GPU 연산하기 (4) | 2023.01.18 |
| [책] Efficient Processing of Deep Neural Network - Ch4. Kernel Computation (2) | 2023.01.17 |
| [Kaggle] Horses or humans dataset으로 이미지 분류하기 (0) | 2022.10.23 |